

このページでは、SEOの基本的な概念やSEOの重要性、また実際に取り組むべき施策について詳しく解説します。SEO初心者の方から実践的な内容が必要な方まで、ぜひ参考にしてください。
イノーバでは、SEOの戦略設計やコンテンツ制作などを含み幅広くサポートする、伴走型マーケティング支援サービスを提供しております。Webマーケティングに課題を感じている方は、ぜひ一度ご相談ください。
SEOとは?
SEOとは「Search Engine Optimization」の略称です。日本語では、「検索エンジン最適化」と訳されていますが、この「最適化」という言葉が、非常に曖昧で分かりにくいかと思います。
SEOを一言で表すと、「検索結果の上位に表示されるために行う、一連の施策」のことです。
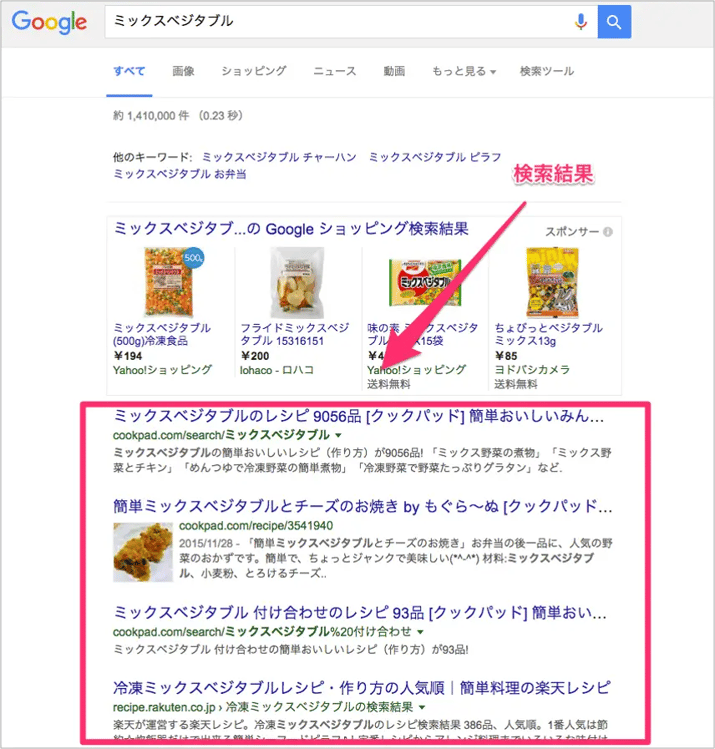
【主な施策】
- 検索者のニーズに応える関連性の高いコンテンツの作成
- キーワード/フレーズのリサーチ
- ホームページの更新頻度を上げる
現状では、「検索結果ページの上の方に表示すること=SEO」という認識が浸透しているため、「SEO対策」という言葉もよく聞かれます。しかし正確には、上位に表示されるように、改善していく施策や取り組みそれ自体をSEOと呼ぶのです。
Webマーケティング施策を検討するときにはSEOのほかにPPCもしばしばテーマとなります。PPCとは「ペイ・パー・クリック(Pay Per Click)」の略で、広告のクリック数に応じて広告主が料金を支払う仕組みの広告手法です。
PPCにはさまざまな種類がありますが、特に検索エンジンにおいて検索キーワードに応じて掲載される「リスティング広告(検索連動型広告)」は、検索エンジンを軸とした広告であることもあり、しばしばSEOと比較検討されます。
SEOはコンテンツを工夫することで、ターゲットとするユーザーが検索したキーワードに応じて上位表示されます。コンテンツを制作したり整えたりするのにコストがかかるものの、検索エンジンに表示してもらううえでは費用はかかりません。
一方で、PPCはGoogleなどに掲載されるたびに料金を支払う必要があります。SEOと異なり有料の広告手法の一つです。SEOとPPCはどちらか一方が優れているというものではありません。Webマーケティングを推進していくうえでは、二つの手法をうまく活用していく事が大切です。
検索エンジンの仕組みって?
SEOを実践する上で欠かせないのが、検索エンジンの仕組みを理解することです。Googleの検索エンジンがWebサイトの情報を収集し、データベース化する機能として「クローラー」と「インデックス」という仕組みがあります。
「クローラー」とは、無数にあるWebサイトを日々巡回し、そのデータやキーワードを集め、データベースに保存する機能です。上記の図では、赤い矢印がクローラーの動きです。
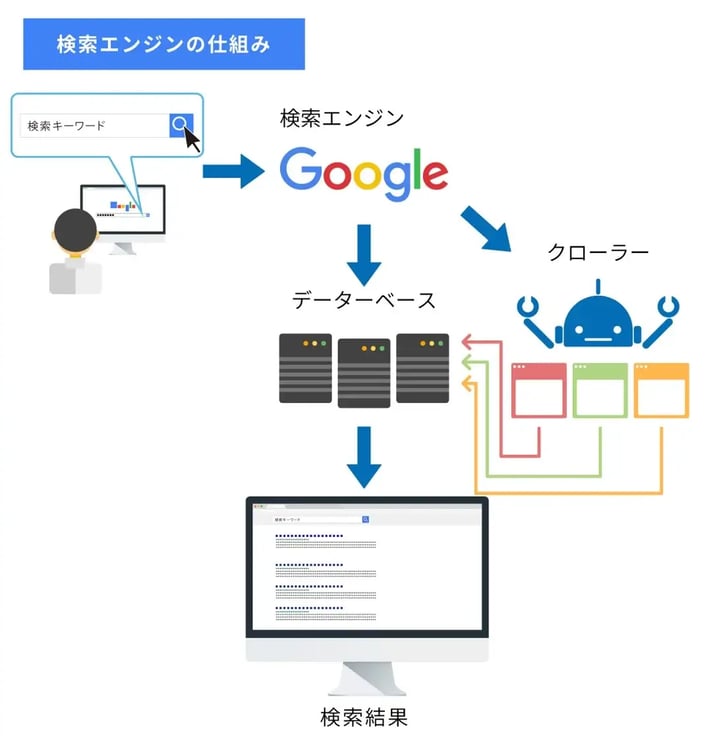
つづいて「インデックス」とは、クローラーで集めたWebサイトの情報をGoogleのWebページのデータベースに登録する機能のことを指します。SEOによる上位表示を実現するためには、大前提としてGoogleのクローラにサイトを発見してもらい、かつインデックスによりデータベースに登録される必要があるのです。
そのうえで、ユーザーが検索したキーワードが、データベースに登録された情報とよく合致している、そしてGoogleにおいて評価が高いWebサイトが検索結果の上位に表示されます。
どういうサイトが検索エンジンの上位に表示されるのか?
検索結果の上位に表示されるためには、検索エンジンにそのページを「良いページ」だと判断してもらう必要があります。この「ページの良い・悪いを判断する基準」を「検索アルゴリズム」と呼びます。
Googleのアルゴリズムがうまく機能することで、ユーザーはGoogle検索を通じて欲しい情報を簡単に手に入れられます。
このアルゴリズムは、何度かアップデートされてきました。アップデートのたびに評価基準が変わっているため、かつては「良いページ」と判断されていたWebサイトが、今も検索結果の上位にいるとは限りません。
検索結果の上位に表示されるためには、このアルゴリズムのアップデートに合わせた適切なSEOをする必要があります。
アルゴリズム変更の歴史を知る
かつてGoogleに良いページだと評価された基準の1つに、「被リンクの数」があります。これはGoogleの創設者、ラリー・ページとセルゲイ・ブリンにより考案されたアルゴリズムです。
当時、大学院生であった2人は「良い論文は、色々な論文や記事へ引用される。これをホームページにも応用できるのでは?」ということに気が付きました。引用された数(被リンク数)が多いホームページは、良いページと判断できると考えたのです。
このアルゴリズムが公表されると、多くの企業が被リンクの数を上げる方法を探り始めました。例えば、ひたすらブログを作って他サイトにリンクを貼ってもらうなどの方法がありました。その作業に時間を取られてしまうので、その被リンク数を上げることを専門にした業者も出てきました。いわゆる「ブラックハット」と呼ばれる手法です。
すると、検索結果の上位には、被リンクの数が多いページだけが表示され、ユーザーが本当に求めている情報が、なかなか出てきません。Googleがアルゴリズムを変更し、また業者がその裏をかく……という“いたちごっこ”の状態がしばらく続きました。
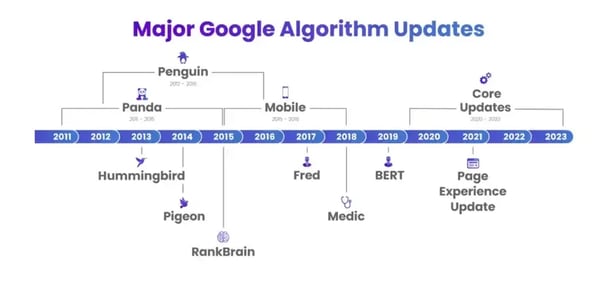
画像出典: https://tinuiti.com/blog/seo/google-algorithm-updates-history-timeline/
そしてついに、悪質なものからグレーゾーンのものまで、検索結果の不正操作にはGoogleからペナルティを課されるようになったのです。
ペナルティを課せられてしまった場合、Googleに解除依頼の連絡をする必要があります。この仕組みにより、悪質な業者の手口が次々と明らかになりました。そして、確立されたのが現在のアルゴリズムです。今のGoogleのWebサイトの評価システムは、数百のアルゴリズムの集合体だと言われています。現在(2023年9月現在)では、被リンクを利用した不正なSEOもペナルティの要因になります。
Googleは明確なガイドラインを公表しているので、これを遵守してWebサイトの作成などを行えば、ペナルティは課されません。
今のアルゴリズムに合ったSEOとは?
2023年9月現在のGoogleの公式見解として、最新の検索アルゴリズムでは文字数の多さを上位表示の評価基準として設定していないと発表しています。
そのため、一つの記事が長ければ良いというわけではなくなりました。むしろ、特定のテーマ(タイトル)について網羅性を広くしたり、あるいは特定のトピックについて深掘りした良質なコンテンツを書くことが重要です。
ユーザーニーズ(ユーザーの検索意図)に沿った観点で、専門性が高く網羅的なコンテンツを入れることで文字数が増えていく、というアプローチがベストです。文字量を稼ぐためにインタビュー記事を量産したものの、検索エンジンに全く評価されなかったという事例も出ています。文字数が増えることの本質を理解せずに、無暗に量を追求しても上位表示には繋がらないということの好例といえるでしょう。
結論として、コンテンツの質が非常に重要だということです。質の高いコンテンツとは「ユーザーにとって価値のある、いいコンテンツを出すこと」といえます。つまり、ユーザーニーズ(ユーザーの検索意図)に沿ったコンテンツを提供することが、上位表示の最短距離の道となります。
SEOが重要である6つ理由
WebマーケティングにおいてSEOが重要な理由は、次の6つに集約されます。
- サイトの集客を増やせる
- リスティング広告では取れないトラフィックを獲得できる
- 検索結果の順位が上がるほど、クリック率(CTR)は上がる
- コンテンツが自社の資産化する
- 自社のブランディング/差別化(ブランド想起やブランディングに効く)
- ネットでの情報収集に対応するため
サイトの集客を増やせる
企業サイトやEコマースなど種別を問わず全般に言えることですが、「サイトに来るアクセスの53%が検索エンジンからの流入」というデータがあります。
多くの企業サイトにおいて、50%超は検索からのサイト流入
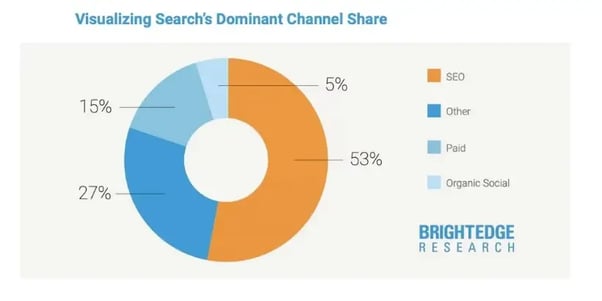
引用元: https://www.brightedge.com/blog/why-seo-2020
サイトの流入経路は検索エンジンの他にも、メールマガジンや、自社のリピーターのブックマークからのアクセスなどさまざまです。そのなかでも検索エンジンは最も強い流入経路なので、ここに注力することでアクセス数や集客数の拡大を実現できます。
メールマガジンなどを活用したメールマーケティングを推進していきたい方は、以下もどうぞ。
参考記事:メールマーケティング完全ガイド
リスティング広告では取れないトラフィックを獲得できる
検索結果画面は、「自然検索結果」と呼ばれる部分と、リスティング広告の部分に分かれています(下記画像では、黄色の部分)。そして、検索した人のおおよそ80%が「自然検索結果」に表示されたWebサイトをクリックしています。
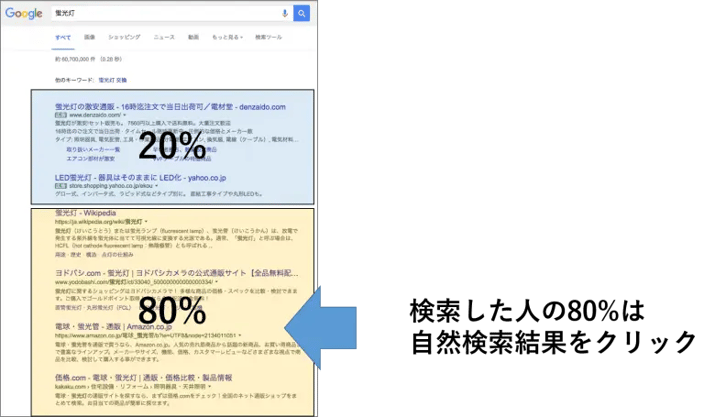
つまり、自然検索結果の中に表示されることによって、多くの人に見てもらいやすくなるのです。
検索結果の順位が上がるほど、クリック率(CTR)は上がる
下記のデータは、検索順位別にクリック率を表したデータです。1位は約30%、上位3位までで50%超となっています。検索結果での順位が上がるほど、クリック率も上がっていくことが分かっています。

実際のデータをみても、検索エンジンにおいて上位表示させることがアクセス数向上に有効であることがわかります。
コンテンツが自社の資産化する
SEOに取り組むと、サイト自体にコンテンツが蓄積し検索エンジンから評価されやすくなります。そして、一度検索結果の上位に表示されるようになれば、コンテンツを一から制作するよりは順位を維持しやすくなります。
上位表示コンテンツからの集客が期待できるため、良質なコンテンツは競争優位の厳選にもなります。つまり、SEOに取り組んでサイトに蓄積されたコンテンツは、自社にとって「お金を生む資産」にもなるのです。
自社のブランディング/差別化につながる
SEOは、自社のブランディングやブランドの想起にも効果的です。ターゲットとするユーザーが検索したときに上位表示されるように対策をしておけば、自社のWebサイトやブランドがターゲットの目に触れる機会が増えるため、認知度の向上やWebの流入回数の増加が期待できます。
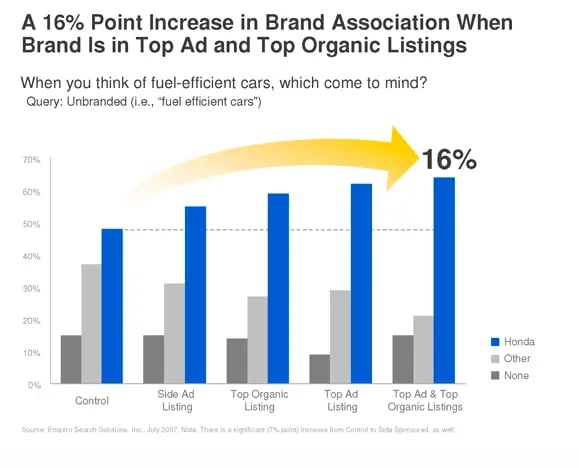
Googleの調査では、検索結果の上位に表示されると、キーワードに対してそのブランドを想起する人が増えることがわかりました。
たとえば「燃費のいい車」というキーワードで「ホンダ」が上位表示されていたときに、燃費のいい車としてどのブランドが思い浮かぶかアンケートを取ったところ、「ホンダ」と回答する人が、16%も増加することが分かりました。さらに、購入意欲も8%ほど上がったそうです。
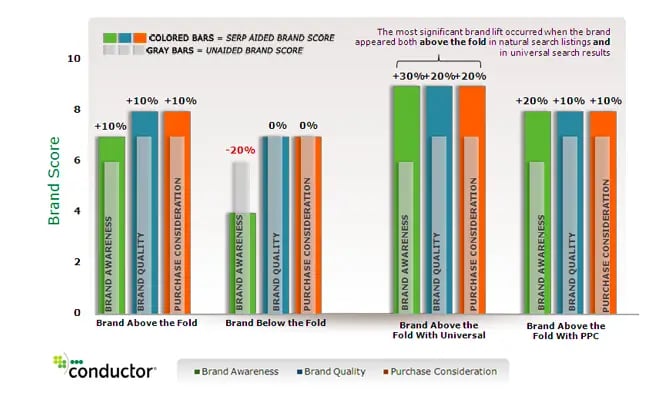
ブランディング強化
また別の調査では、スクロールせずに見れる画面(検索結果の上位)に表示されるとブランド想起率は10%向上しました。さらに、画像や動画などと一緒に検索結果が上位に表示されると、そのブランド想起率は30%も改善しました。
ネットでの情報収集に対応するため
今では、欲しい商品の情報をインターネットで収集することが当たり前の時代になりました。実際に、70%近くの人が、インターネット検索によって新商品の情報を入手しているそうです。
そして、多くの人が検索エンジンで検索することから、情報収集を始めています。だからこそSEOに取り組んで、多くの人に見てもらえるように対策することが重要なのです。

SEO準備編
これまでの内容で、SEOの重要性については、ご理解いただけたかと思います。ではここからは、具体的にやるべき施策について、解説していきたいと思います。
グーグルは何を検索評価の指標にしているのか?
第1章にて、検索エンジンに高く評価してもらうには「アルゴリズムに合った施策を行うこと」が重要だとお伝えしました。では、具体的にはどんなポイントが検索評価の指標になっているのでしょうか?
実は、Googleはそのアルゴリズムやサイトの評価指標を明らかにしていません。しかし、「このようなサイトが高く評価されやすい」という傾向を、外部から分析することは可能です。主な評価ポイントは以下の通りです。
ポイント1:サイトの分かりやすさ
- 見出し、小見出し、ナビゲーションの為のリンクがあるか、などサイトの内部構造
ポイント2:コンテンツ自体がいいものか
- 関連するキーワードが入っているか
ポイント3:ページの強さ
- 外部リンクの数(被リンクの数など)
- 内部リンクの数(アンカーテキストリンクなど)
ポイント4:SNSでのシェア数
- Twitter、フェイスブックなどSNSでのシェア数
※SNSでシェアされたリンクについては、Googleはリンクとして見なしていません。しかし、ソーシャルシグナルとして考慮はされています。また、ソーシャルで多くシェアされるということは、結果的にリンク獲得にもつながるのでソーシャルでのシェア数は重要と考えるべきでしょう。
ポイント5:E-E-A-T
- 経験(Experience)や専門性(Expertise)や権威性(Authoritativeness)、信頼性(Trust)が高いコンテンツが高評価に
- YMYL(金融や医療などの生活やお金に関連するトピックを扱うコンテンツ)では特に重視される傾向に
参考記事:SEO対策で重視すべきE-E-A-Tとは? 重要性や高めるポイントを解説
ポイント6:スマートフォンなどモバイルでの使いやすさ
- スマートフォンなどモバイル版で見やすい、使いやすい優れたコンテンツか
- 2021年3月からMFI(モバイルファーストインデックス)が導入されて以降重要性が高まった
ポイント7:フレッシュネス
- 一次情報・オリジナリティの高い情報が豊富な方が評価されやすい
・自分が初めて発信した情報
・体験して得た情報
・自身で行った調査や実験の結果など
ポイント8:ページスピード
- ページの読み込みスピードが早い方がユーザビリティが高いため評価されやすい
以上が、主な評価ポイントと推測されています。実際の指標は、さらに多くの要素を考慮して判断されており、かなり複雑な基準に基づいて、サイトの評価がされていると考えられます。
内部対策と外部対策、コンテンツ制作
これらの評価指標を考慮した上で、どのようにSEOに取り組むべきでしょうか?
やるべき施策は、主に下記の3つに分けることができます。
内部対策(On-page SEO)
主に、内部リンクやサイトの構成を改善することによって、検索エンジンから評価されやすいページを作る施策のことです。例えば、アンカーテキストにキーワードを含めたり、検索結果画面に説明文として表示される可能性が高い「メタディスクリプション(meta description)」の内容を選定する施策のことです1。
外部対策(Off-page-SEO)
外部対策とは、自社サイトの外からの評価を高める施策のことです。前述したように、「どのようなサイトからリンクを受けているか」も、ページの評価を高める重要な要素の1つです。かつてのブラックハットのようにリンクをお金で買う施策ではなく、Webサイトが提供するコンテンツや価値の力によって自然な方法で多くの被リンクを獲得することが大切です。
SEOで高い効果を得るためには、この内部対策と外部対策の両方を行う必要があります。
コンテンツ制作(信頼性明示)
最後にユーザーの検索ニーズに合致していて、かつE-E-A-Tを考慮した良質なコンテンツを制作することが大切です。
Googleのガイドラインにおいては以下のような記載があり、ユーザーのニーズを高いレベルで満足させるコンテンツが高評価につながることがわかります。
以上の3つの点を意識することで、Webサイトの評価が向上し検索エンジンでの上位表示が実現します。
SEO実践編
目標を定める
まず、「何のために対策をするのか?」という目標を明確にしましょう。SEOに取り組むことによって、最終的に達成したいことは何でしょうか。この目標は、後の効果測定の分析やKPIにつながる重要な項目なので、具体的かつ明確な目標を設定しましょう。
会社によっても、SEOに取り組むことによって達成したい目標はさまざまだと思います。ちなみに、下記のデータは「SEO戦略の最も重要な目標」を聞いたアンケート結果です。
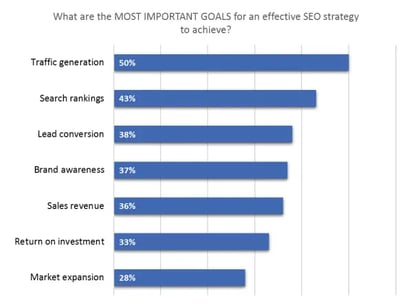
【SEO施策の最も重要な目標は?】
1位 トラフィックの流れの形成(55%)
2位 検索順位(43%)
3位 コンバージョン獲得(38%)
4位 ブランド認知(37%)
5位 投資対効果(≒売上拡大などコストに見合う効果の実現)(33%)
6位 市場の拡大(28%)
全体の流れを理解する
次に、全体的な流れを理解しましょう。
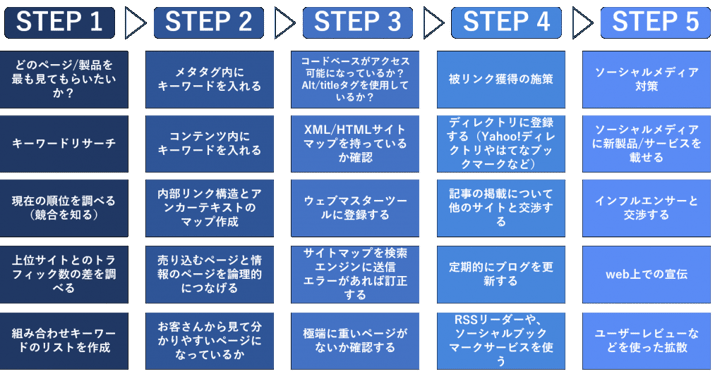
【STEP1】
STEP1は、「キーワード作り」です。自社ページから始まり、現状分析、キーワードリストのアウトプットまでを行います。まずは、自社のページの中で、「どのページ/製品を最も見てもらいたいか」を決めましょう。次に、ユーザーがどんなキーワードで自社サイトにたどり着いているかをリサーチします。(5-1「キーワードリサーチ」)また、現時点での自社サイトの順位や競合の順位も、調べておきましょう。Googleの「キーワード プランナー(Keyword Planner)」などのツールを使用して、複合キーワードのリストも作成します。
【STEP2】
STEP2はサイト構造です。検索エンジンにとって見つけやすく、理解しやすいサイト構造を作ります。まず、タイトル(title)タグやメタタグ(meta description、h1、h2タグ)内と、コンテンツ内に対策したいキーワードを入れます。ただし、コンテンツ内にキーワードを詰め込みすぎると、不自然になってしまうので、気をつけましょう。
次に、サイト全体で内部リンクがどのように張られているか分かるように、「サイト構造図」を作ります。そして、サイト内で情報を提供するページと、売り込むためのページを自然な形で繋ぎます。最後に、「ユーザーから見て、分かりやすいページになっているか」をもう一度、確認しておきましょう。
【STEP3】
STEP3は、検索エンジンへサイトを登録するステップです。最初に、「検索エンジンからのアクセスが可能な設定になっているか」を確認します。また、「何の画像なのか」を検索エンジンに適切に伝えるために、タグや
ここで何らからのエラーが返ってきたら、修正しましょう。「極端に重いページがないか」もチェックしておきます。
【STEP4】
そして次に、外部からの被リンク対策をしていきます。この対策を行っていない企業も多いですが、一定の効果が見込めるので、取り組むことをおすすめします。
外部対策の代表例では、他のサイトとの記事の掲載について交渉をしたり、定期的なブログの更新、ソーシャル型RSSリーダーやソーシャルブックマークサービスを使う、などの方法があります。
RSSリーダーとはWebサイトの更新情報を配信するための機能のことで、さらに更新情報をWeb上に発信するのが「ソーシャル型RSSリーダー」です。同サービスを利用すれば、他のユーザーがRSSの情報を購読することで、外部サイトからの被リンク獲得につながります。
ソーシャルブックマークとは、自分のブックマークをネット上に公開し、不特定多数の人間と共有する機能のことで、登録するとそのブックマークサービスから被リンクを獲得できます。さらに、不特定多数の方にURLが共有され、認知度の向上やアクセス増加にも役立ちます。
なお、「はてなブックマーク」などのディレクトリ型サイトへの登録も、外部対策の1つですが、その効果についてはさまざまな意見があります。ディレクトリ型サイトの中には登録が有料のものもあるので、費用対効果を考慮した上での登録をおすすめします。
【STEP5】
最後に、ソーシャルメディア(SNS)対策です。まずは、自社のプロフィールやページに新製品/サービスを載せます。次に、その分野で影響力を持つ(フォロワーが多いなど)「インフルエンサー」と呼ばれる人との関係を作ったり、ネットでプレスリリースを公開するなどの方法で、コンテンツを拡散させる仕組みを、作りましょう。
また、もう少し高度な方法では、口コミなどのUGC(ユーザー生成コンテンツ:User Generated Contents)を増やしていく方法もあります。グルメサイトなどが強い理由は、このUGCが充実しているからです。口コミが雪だるま式に増えていくので、コンテンツに対する信頼度が上がり、結果として上位に表示されるのです。高度ですが、SEO効果も非常に高い方法です。
以上が、全体の流れです。この中で、特に自社が注力するべき部分を洗い出し、リソースの配分などの戦略を立てていきましょう。
SEOのポイント
それでは次に、各ステップでの特に重要な対策について、詳しく解説していきます。
キーワードリサーチ
SEOの最初のステップにおいて、非常に重要なのが、キーワードリサーチです。キーワードを分析することで、ユーザーの検索目的や、自社の製品/サービスの隠れたニーズを知ることができます。
まず、自社がどのキーワードで検索されているのかを調べてみましょう。Google Analyticsなどの無料ツールで簡単に分析することができます。ここで、「検索して欲しいキーワードと、実際に検索されているキーワードに違いがないか」も調べておきましょう。
また、そのキーワード自体の人気も非常に重要です。キーワードの人気が高ければ、それだけ多くのユーザーがページに訪問してくれます。さらに、キーワードの派生語(組み合わせ)も、ユーザーのニーズを知る貴重な情報源です。Googleのキーワード プランナー(Keyword Planner)などのツールを使うと、これらの情報を分析することができます。
そして、キーワードリサーチの際に注目すべきポイントは、「ロングテールキーワード」です。ロングテール(長い尻尾)キーワードとは、「さまざまな組み合わせで検索されるキーワード」のことです。例を挙げて説明しましょう。イノーバがお客さまに向けて支援サービスを提供している「コンテンツマーケティング」という言葉は、ヘッドワード(ロングテールの“尻尾”に対して、こちらは“頭”)と呼ばれます。コンテンツマーケティングを検索する人の中には、ただ単にその意味を知りたいだけの人、外注できる業者を探している人、コンテンツマーケティングの会社への就職を考えている人など、さまざまです。
しかし、「コンテンツマーケティング 会社 比較」や、「コンテンツマーケティング 月額」などで検索する人は、コンテンツマーケティングに取り組もうと決めていて、業者選定の段階に入っていると考えられます。ロングテールキーワードは、全体の検索量は多くありませんが、コンバージョン獲得に繋がりやすい、質の高いアクセスなのです。
下記のグラフは、ヘッドワードとロングテールキーワードの、コンバージョン率を表してます。ヘッドワードの10.60%に対して、ロングテールは26.07%のコンバージョン率なので、その差は歴然です。
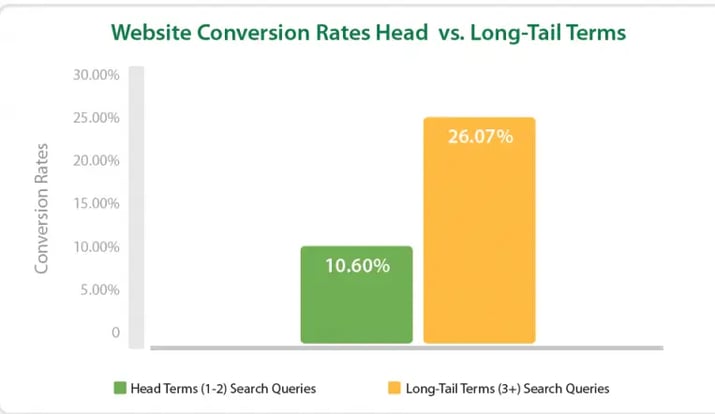
画像出典:http://neilpatel.com/2015/12/22/7-brilliant-examples-of-brands-driving-long-tail-organic-traffic/
また、CTR(クリック率)にも大きな違いが出ています。ヘッドワードでは検索結果の1位に表示された場合のCTRは、約18%。一方で、ロングテールキーワードで1位に表示されると、CTRは30%以上になります。また2位以降を見ても、全体的にロングテールキーワードの方が、高いCTRになっています。
アクセスの7割はロングテール
.webp?width=513&height=277&name=%E3%82%A2%E3%82%AF%E3%82%BB%E3%82%B9%E6%95%B0%E3%81%AE7%E5%89%B2%E3%81%8C%E3%83%AD%E3%83%B3%E3%82%B0%E3%83%86%E3%83%BC%E3%83%AB%E3%81%8B%E3%82%89%E3%81%AE%E3%82%A2%E3%82%AF%E3%82%BB%E3%82%B9%20(1).webp)
画像出典: http://www.wordstream.com/blog/ws/2016/05/10/google-ctr
また、サイトへ流入してくるアクセスの約70%は、ロングテールキーワードだというデータも出ています。
ヘッドワードは全体の検索量が非常に多いので、多くのユーザーを獲得するために、ついヘッドワードばかりを狙ってしまいがちです。しかし、検索量が多いということは、それだけ競合も多いということ。キーワードを選定する際は、「クリックされやすい」かつ「コンバージョン率も高い」ロングテールキーワードにも注目し、対策をすることで、全体の集客や売上を改善することも可能なのです。
コンバージョンについては以下をどうぞ
Googleでは、2020年にGA4「Googleアナリティクス4プロパティ」をリリースしています。これまでのGoogleアナリティクスは「ユニバーサルアナリティクス(UA)」という名称で、GA4はその進化版にあたります。
GA4の導入によって、以下のような機能が拡充されています。
- Webとアプリを横断的に分析
- Googleの機械学習能力を活用した予測機能
- BigOueryへのデータエクスポートの無償化
- GDPR(EU一般データ保護規則)やCCPA(カリフォルニア州消費者プライバシー法)に準拠
すでにユニバーサルアナリティクスは、2023年7月1日に停止されているので、2023年9月現在ではGA4で分析をすることになります。
現状診断と競合分析
次に、現状診断と競合分析です。対策したいキーワードでは現在、どこが競合なのかを見てみましょう。「実際の現場での競合=WEB上での競合」とは限りません。お客さんがそのキーワードで検索した時に、「どこの企業と比べられるのか」を知る必要があります。
競合をいくつかリストアップしたら、それらの他社のコンテンツ量や、被リンクの数などを分析します。無料で使える、競合サイト分析ツールなども多くあります。分析できる情報はツールによって異なりますが、主にユーザー数、セッション数、平均滞在時間などが分かります。
内部の被リンクを構築する
SEOの内部対策で、非常に効果的と言われているのが「内部リンクの構築」です。内部のリンクを増やすとは、どういうことでしょうか?
内部リンクとは、同じドメイン内のページをリンクで結ぶことです。例えば、「詳しくはこちら」と書かれた部分に貼ってあるリンクや、専門用語などにリンクが貼ってあり、クリックすると用語解説のページが開くリンク(アンカーテキストリンク)なども、全て内部リンクです。
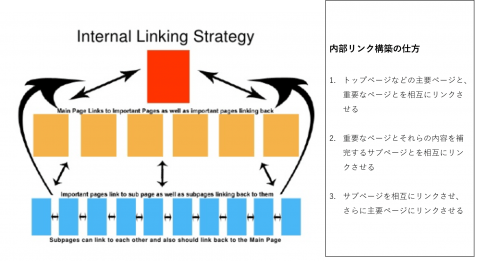
訳:イノーバ
では、なぜ内部リンクを構築することがSEOに有効なのでしょうか?
検索エンジンがページの信頼性を評価する基準の1つに、「被リンクの数」があります。「たくさんのサイトに引用されている=良いサイト」だと判断するのです。そして、違うサイトからだけでなく、自分のサイト内でも引用すると、検索エンジンはそのページを重要だと判断し、信頼性が上がるのです。
内部リンクの構築には主に、以下の利点があります。
画像出典: https://www.orbitmedia.com/blog/internal-linking/
訳:イノーバ
- 簡単に、早く、無料で構築できる
- 外部リンクに比べてコントールしやすい
- Googleに重要ページを示すことができる
- サイト訪問者を、よりコンバージョン率の高いページへ誘導できる
- CTA(行動喚起)への誘導を高める
かつては、内部リンクをたくさん貼るだけで、検索順位を上げることは可能でした。しかし、現在のアルゴリズムでは、この方法は効果的ではありません。今の内部リンクに必要なのは「サイトの読者から見て分かりやすく、自然な形で貼ってあること」です。意図的に張られたリンクではなく、ナチュラルリンクと呼ばれるリンクです。
もう1つ、大切なことは、それぞれのリンクで繋ぐそれぞれのページに関連性があることです。下の図のように、キーワードごとにページをグループ化してみましょう。そして、同じグループ内のページ同士をリンクで繋ぎます。

画像出典: http://www.slideshare.net/DemandWave/why-your-link-building-doesnt-work
訳:イノーバ
このような内部リンクの構築をすることによって、ユーザーにとって、使いやすいだけでなく、検索エンジンのクローラーにとっても、分かりやすいサイトを作ることが出来るのです。
また、効果的な内部対策の1つとして、「ヒーローページを作る」という方法があります。ヒーローページとは、自社のサイトの中で「特に上位に表示させたいページ」のことです。
その他の施策では、ブログ開設も有効な方法です。単純にサイトのページが増えるだけでなく、ブログ内のカテゴリーからそれぞれの記事にリンクが貼られるので、内部リンクも増えます。サイト自体が、自然と内部リンクができやすい構造になるのです。
外部の被リンクを構築する
では次に、外部の被リンクを構築してみましょう。検索エンジンは、内部リンクと比較すると、外部リンクにより評価の重点を置いています。なぜなら、内部リンクが自己評価だとすると、外部リンクは他己評価だからです。自分で「良いサイトだよ」と言っている評価よりも、他の人が「ここは良いサイトですよ」と言っている評価の方が、信頼できますよね。
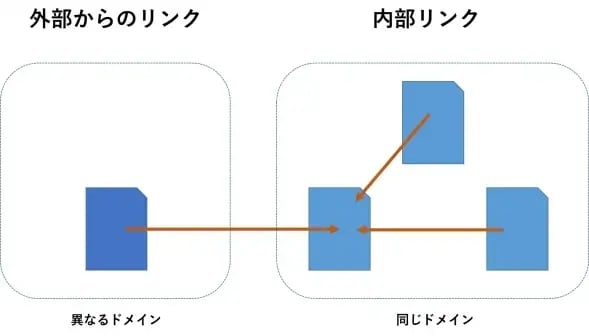
外部リンクの獲得において、いわゆる「ブラックハット」と呼ばれるリンクを買う施策(人工リンクとも呼びます)は、ペナルティの対象になり、ガイドラインで禁止されています。例えリンクを買おうとしても、Googleの取り締まりも非常に厳しくなっているので、不可能に近いです。
では正しい方法で外部サイトからの被リンクを集めるには、どうすればいいのでしょうか。まず、取り組むべきことは、「いいコンテンツを作ること」です。「1-5 今のアルゴリズムに合ったSEOとは?」で紹介したように、今は「コンテンツ重視」の時代です。どんなに外部対策をしても、コンテンツが良質でなければ、被リンクを獲得することはできません。
コンテンツを作成したら、次に他のサイトへアプローチをしていきます。以下の方法が、主な施策です。
- 自社が所有しているサイトからリンクを貼る
- Web上で多く拡散されそうなコンテンツを作る(面白コンテンツや、時事ネタなど)
- ニュースサイトやキュレーションメディアなどに、記事を書かせてもらうように依頼する(ゲストブログ)
- その分野で影響力を持つブロガーや、インフルエンサーと接点を持ち、自社と関連性があるサイトにリンクを貼ってもらう
ただ、これらの施策を地道に続けていくことは、非常に時間と労力を要します。最も大切なことは、自社のサイトが「良質なコンテンツを持っていること」です。リンクを買うことが不可能となった今、外部からの被リンクを獲得するために最も有効な方法は、「読者に役立つ、良質なコンテンツ作成」しかないのです。

その他お勧め施策
コンテンツマーケティング
今の時代で、効果的なSEOの1つが「読み手視点での、コンテンツ作成」です。検索エンジンがコンテンツの質を重視するようになった為、コンテンツマーケティングは効果的なSEO対策にもなるのです。
特に「オウンドメディアとブログの開設」は、自社サイトのページ数や内部リンクを増やすことができるので、SEO対策におすすめです。また、ブログCMS(WordPressなど)を利用すると、SEOの内部対策などを自動で行ってくれます(CMSについて詳しくは、こちらの記事をご参照ください)。
パンくずリスト
パンくずリストとは、サイト内での現在地を階層順に表示しているリストのことです。通常ページの上部に表示されていて、それぞれの階層にはリンクが貼られています。

特にページ数の多いサイトでは、このパンくずリストの設置は、有効な施策の1つです。
まず、対策したいキーワードを表示し、それぞれを階層を示すアンカーテキストリンクにすることで、内部リンクを増やすことができます。
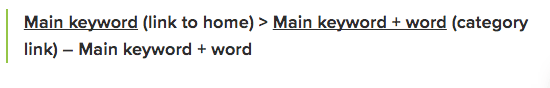
画像出典: https://www.searchenginejournal.com/breadcrumbs/15022/
また、ユーザーに対しても分かりやすいサイト構造になるだけでなく、Googleのクローラーにサイト構造を教えることもできます。さらに、検索結果にもこのパンくずリストは表示されるので、訪問者の獲得にも繋がります。
結局、何からやるべき?
ここまで色々な対策を紹介しましたが、SEO初心者の方やこれから本格的な施策に取り組もうとしている方は、「結局、何をすればいいんだろう?」と悩んでしまうかもしれません。
下記のデータは、それぞれの対策の効果と難しさを表したものです。
<最も効果的なSEO>
1位・・・トラフィックの流れの形成
2位・・・検索順位
3位・・・コンバージョン獲得
4位・・・ブランド認知
<最も難しいSEO>
1位・・・検索順位
2位・・・トラフィックの流れの形成
同率2位・・・投資対効果
4位・・・コンバージョン獲得
繰り返しになりますが、今の時代のSEOで最も大切なことは、「コンテンツの質の高さ」です。これから本格的にSEOに取り組む方は、まず難易度がそれほど高くなく、効果も出やすい「キーワードリサーチ」から始めることを、おすすめ致します。ターゲットとなるキーワードを選定した後、そのキーワードに関連したコンテンツ作成に、取り組むのが良いでしょう。
目標設定と改善の進め方
KPI(重要業績評価指数)とは、大きなビジネスゴールを達成するための、「中間指標」のことです。この数字を追いかけることによって、結果として売上や利益の改善に繋がります。
SEOへの取り組みを売上や利益に繋げるには、明確な目標とKPIの設定が欠かせません。「何を達成するために、SEOに取り組むのか?」「その目標にたどり着くまでに、どんなステップが必要なのか?」を、必ず把握しましょう。
どの指標を見る?
企業によって「SEO対策の目標」は異なります。よって、「どの指標を見るべきか」という点も、さまざまです。他の企業がどの指標を見ているのか、下記のデータから参考にしても良いかもしれません。
<もっとも役に立つ、SEOの効果測定法は?>
1位・・・Webトラフィック(54%)
2位・・・獲得した見込み客の数(50%)
3位・・・サイト訪問者のコンバージョン率(47%)
4位・・・キーワードの検索順位(44%)
5位・・・ページ滞在時間/エンゲージメント(26%)
目標とKPI設定
では、実際の目標とKPIを見てみましょう。残念ながら、全ての企業やビジネスに当てはまるKPIはありません。自社の現状や、課題点、目的などを精査し、目標とKPIを設定しましょう。以下は、ある企業の目標とKPIの例です。
参考資料:https://searchmarketingcorner.wordpress.com/2010/12/17/SEO-strategy-plan-objectives-kpis/
「大きな目標」と「それを達成するための手段(KPI)」に分けると、やるべきことが整理されるので、非常に分かりやすくなります。
また、ECサイト大手である「Yahoo!ショッピング」は、主なKPIを以下のように設定しているようです。(出典:http://Web-tan.forum.impressrd.jp/e/2016/07/05/22914 )
・検索数
・IMP(広告表示回数)
・クリック数/クリック率
・流入数
どうやって改善を進める?
目標や見るべき指標(KPI)が決まったら、それらに基づいて数値を計測し、分析していきましょう。SEOでは「PDCAサイクル」を高速回転させることが非常に重要です。目標に基づいた戦略を立て、実行し、小さな改善を繰り返すことで、SEOの効果が表れます。
<SEO改善の10ポイント>
出典: http://searchengineland.com/10-fundamental-tips-to-improve-your-SEO-14024
1. SEOのファーストステップは、「キーワードリサーチ」
→サイトに来てもらいたいユーザーは、どんなキーワードで検索していますか?そのキーワードがコンテンツに入っていますか?
2. 信用できるサイトから、正しいSEO情報を集めましょう
インターネットのSEO情報には、間違っているものが存在します。また、検索アルゴリズムはどんどん変化していくので、古いSEO情報だと役に立たない可能性もあります。
3. サイトのコード記述に気をつける
CSSなどを使用して、検索エンジンが理解しやすいサイトになっていますか?
4. ナビゲーションを分かりやすく
検索エンジンは、シンプルなテキストリンクを好みます
5. 信頼できて、関連性のあるサイトからリンクをもらう
リンクは「量」よりも、「質」を重視しましょう
6. サイトマップページを作る
検索エンジンに、各ページを見つけてもらいやすくなります
7. 技術的な問題は、専門家に聞く
SEOの効果が出ていないのは、技術的な問題である可能性もあります。技術に詳しい人や、会社に相談してみましょう。
8. ツールを使って、自分の進捗状況を把握する
Google Analyticsは無料で多目的に使えるので、おすすめです。
9. 検索エンジンに自分の居場所を知らせる
XMLサイトマップなどを登録すると、継続的にサイトの状況を、検索エンジンに知らせることができます。
10. 「コンテンツが王様」ということを忘れずに
「質の高いコンテンツを作ること」「それを定期的に更新すること」。この2つが、今のSEOにおいて、非常に重要です。
以上の10ポイントは、改善の一例です。目標やKPIと同様に、自社の状況などを考慮しながら、改善すべき部分を見つけていきましょう。
最近の傾向
最近の動向でいうと、AI予測技術がSEOに与える影響は大きいと見込まれます。AIを通じて将来のデータやトレンド予測精度が格段に向上します。これまでよりも先回りしてコンテンツ施策を検討したり、制作を進めたりできるようになるわけです。
Googleでは、検索結果画面においてSGE(Search Generative Experience)という生成AIを使った新しい検索回答を表示する取り組みが開始され、日本でも2023年8月30日より試験利用が可能となっています。順調にいけば2024年には本格導入される見込みです。
AIを活用した回答表示が普及すれば、SEOのトレンドが大きく変化する可能性もあります。
SGEの回答結果には引用されたサイトのリンクも表示されますが、SGE内で引用元となるWebページの評価基準と既存のSEO検索順位の評価基準は異なります。
今後はSEOでの上位表示に加えて、SGEの引用サイトの評価基準を研究したうえで、引用元リストでも先頭に表示されるように工夫する必要が出てきそうです。引用先としての評価を高めるためには、SEO以上に記事の網羅性とE-E-A-Tがより重要になってくると考えられます。
SEO対策にかかる費用の相場とSEO会社のサービス体系
ここまで検索エンジンの仕組みやSEO対策の基本、具体的な手法について解説してきましたが、実際に自社で対策を行うにはノウハウやリソースが足りないという方も多いかもしれません。
イノーバを含め多くのマーケティング支援を行う企業では、SEO対策のコンサルティングや支援を行っています。自社で対策を実行するのが困難だと感じたら、このようなサービスを利用するのも一案です。
ここで、自社でSEOを行う場合と、外注する場合のメリット・デメリットを整理しておきます。双方を比較して、自社のSEO対応方針を確定させましょう。
自社でSEO対策を進める時のメリット
- 外注費用がかからない
- 社外とのコミュニケーションが発生しない
- WebマーケティングやSEOのノウハウが蓄積する
自社でSEO対策を進める時のデメリット
- SEOやマーケティングに精通した専門家が必要
- 専門部署やチームが必要になり、本業に割けるリソースが減る
- ノウハウが不足していると効果がでないリスク
外注でSEO対策を進めるときのメリット
- 専門家の活用によりスピーディに効果を発揮する可能性が高い
- 本業に集中できる
- 客観的な視点でWebサイトを評価・改善してもらえる
外注でSEO対策を進めるときのデメリット
- 費用がかかる
- 社外の人間とのやり取りが増えて負担になる
- 自社のビジネスや市場環境の理解不足で失敗するリスクがある
以上のメリット、デメリットをふまえると、SEO会社に外注した場合の費用が重要なポイントとなるでしょう。具体的には、対策の内容やSEO会社のサービス体系によって異なってくるところですが、以下の記事ではSEO会社が提供する主要なサービス内容とその相場についてまとめ、効果の高いSEO対策について解説しています。外注を検討されている方は是非一度お目通しください。
SEO対策支援事例
株式会社ベック|明確なペルソナ設定とキーワード選定で、法人向けECサイトでの顧客単価が60%増
株式会社ベックは缶バッジの製作用パーツと缶バッジマシンの販売をECサイト「バッジマンネット」を通じて行っているメーカーです。従来は「バッジマンネット」内のブログページで、缶バッジの魅力や缶バッジのビジネス活用方法などの記事を公開してきたものの、マーケティング効果は不透明でした。
イノーバのBtoBマーケティング伴走型支援サービスを依頼。
同社はECサイト専業でビジネスを展開しているため、オーガニック検索によるブログページへの集客と購入ページへの遷移が売上向上につながると考え、イノーバとともに記事コンテンツの強化に乗り出しました。
ブログコンテンツを質・量ともに充実させた結果、3カ月のアクセス数が前年比で+63%、オーガニック流入は+95.7%、ユーザー数は+76%など、ブログの流入数とECサイトへの誘導に成功しました。これらの施策は売上にもつながり、顧客単価を約60%アップさせることに成功しました。
続きはこちらから
株式会社WOOC|SEO未経験から4ヶ月で自然流入数が倍増。内製化も目指した自走力も養えるイノーバの伴走支援
株式会社WOOCは休眠不動産の収益化を支援する新しい不動産会社です。コワーキングスペースとレンタルオフィスのシェアオフィス事業の「BIZcomfort」、レンタルオフィス事業の「BIZcircle」が事業を行っています。
そのようななか、BIZcomfortの知名度を上げるべくイノーバの伴走型支援を受けることになりました。もともとコンテンツマーケティングは未経験で、WebサイトはコンテンツSEOがされていない状態でした。
そこで、イノーバの支援のもと、セグメントやターゲット設定といった戦略設計やコンテンツ制作を進めることにしました。現在、BIZcomfortのサービスサイト上にコラムサイトを立ち上げ、コラム月4本の納品をイノーバが受け持っています。また、公開したコラムのパフォーマンス分析等を通じて今後の施策の方向性なども相談しています。
コラムの納品後、数カ月経過した時点で目標の倍以上のセッション獲得に成功するなど、高い成果を挙げています。また、読まれにくいコンテンツは改善を出してもらうなど、納品後のフォローもSEO対策に役立っています。将来的にはイノーバの支援から得たSEOの知見を活かして、コラム制作を内製化したいと考えているところです。
続きはこちらから
SEOに関するFAQ
Q1 SEO的にはページ数が何枚あるのが良いのか?
A:重要なのはページの数ではなく、コンテンツの質です。
「Googleの使命は、世界中の情報を整理し、世界中の人がアクセスできて使えるようにすることです。」
と、上記からGoogleの思想を鑑みると、何をすべきか理解できます。
つまり、ユーザーが求めている情報ページの数よりも、コンテンツがしっかりと、自然な形でリンクを集めているほうが、SEOには効果的です。
Q2 URL表記はSEOに効くのか?
A:英語であれば、有効です。ただし、日本語は注意が必要です。日本語は2バイト(ダブルバイト)文字になるので、日本語をURLに入れると、URLが長くなり、Googleが読み込みにくくなってしまいます。ひらがな数文字程度の短い日本語であれば、入れてもいいかもしれませんが、おすすめはできません。
Q3 外部ブログなどでSEO対策をするにはどうすればいいのか?
A:基本的に「良いコンテンツを上げる」「リンクを取る」という2つの原則は、変わりません。外部ブログの最大のメリットは、ドメインが強いのでGoogleで評価されやすく「アクセスを集めやすいこと」です。一方で、最大のデメリットは「リードを獲得する為の仕組みを作りにくい」ところ。アクセスを、どう売上に繋げるかが、外部ブログを利用する上での、一番の課題です。
しっかりと対策するのであれば、やはり自社のサイト内でブログを開設する方が、有効でしょう。
Q4 メタディスクリプション(meta description)の文字数は何文字まで?
A:全角で124文字程度です。それ以上になると、省略されてしまうので気をつけましょう。
Q5 httpsはSEOに効くのか?
A:2014年8月にGoogleは、httpsをランキングシグナルに使用することを、公式発表しています。 https://Webmasters.googleblog.com/2014/08/https-as-ranking-signal.html
よって検索結果の順位においては、SSL化されているサイトの方が優遇されやすい、と言えます。
Q6 SEOに効果的なWordPressテーマは何か?
A:かつては、「WordPessはSEOに強い」という神話がありました。しかし、今はGoogleのクローラーの性能がかなり上がっているので、記事の中身を分析しています。よって、テンプレートにこだわる必要はありません。
今はコンテンツの質を重視しているので、テキスト要素の配置も考えられたテンプレートを使用するのが良いでしょう。この対策をきちんとしているCMSであれば、WordPess以外のテンプレートでも、SEOに効果的です。
Q7 SEOスパムって何のこと?
A:検索エンジンを騙すためにやるテクニックを総称して、「SEOスパム」と呼びます。かつては、良いSEO会社か悪いSEO会社かを見極める為にも、スパムに対する知識を身につける必要がありました。
しかし、今は「良いコンテンツを上げること」が最も重視されているので、スパムの知識がなくても、充分に対策することができます。
Q8 SEOに詳しくない初心者が最初に読むべきサイトや本は?
A:SEOを最初に勉強する際に、おすすめなのは「10年つかえるSEOの基本」(著:土居健太郎)です。ページ数は多くないので、とても読みやすいかと思います。もっと言うと、今は、コンテンツSEOの時代ですから、これくらいの知識量で十分なのです。分厚いSEOの本は買う必要がありません。
SEO初心者の方におすすめする方法は、「とにかくやってみること」です。本やサイトで知識を身につけることも大切ですが、「運用、分析、改善」というPDCAサイクルを実際に回す方が重要度は高いので、とにかく運用してみることをおすすめします。
Q9 被リンクとバックリンクは何が違うのか?
A:色々な呼び方がありますが、基本的に「被リンク」「バックリンク」「インバウンドリンク」は、全て同じ意味です。
Q10 メタキーワードタグの中に、キーワードは入れるべき?
A:かつては、メタキーワードタグを検索エンジンが見ていましたが、今はもう見ていません。よって、キーワードタグにはキーワードを入力しなくても、検索結果の順位には影響ありません。
むしろ、ここにキーワードを入力すると、競合企業に狙っているキーワードを教えることにもなるので、注意が必要です。
Q11 「アンカーテキスト分散」ってどういうこと?
A:同じキーワードだけに、アンカーテキストリンクを貼っていると「不自然なリンク」として、検索エンジンから評価されてしまいます。それを防ぐために、キーワードそのものだけではなく(例:コンテンツマーケティング)、フレーズやブランド名などを含めて分散させる方法(例:コンテンツマーケティングって何?など。)が、アンカーテキスト分散です。
アンカーテキストを設定する際には、同じキーワードだけにリンクを貼っていないか、チェックしてみましょう。
Q12 成果報酬型だというSEO会社から勧誘されたが大丈夫か?
A:基本的には、「注意した方がいい」でしょう。成果報酬型のSEO会社はほとんどなくなった、と言われていますが、まだ残っている会社もあります。
かつては中小企業を中心に、成果報酬型と謳ったSEO会社と契約してしまうケースが、多くありました。成果報酬型と言いながらも、実際は禁止されているバックリンクを大量に貼っているので、当然企業はGoogleから、ペナルティを受けることになってしまいます。
成果報酬型だというSEO会社と契約する際は、「リンクの購入でないか」「ペナルティを受けた時の責任の所在」などを、確認しておきましょう。
まとめ
インターネットの普及により、消費者の購買行動に大きな変化が訪れています。今では、7割近くの人が、新商品の情報をインターネットで得ています。そして、インターネットでの情報収集の際に、多くの人が利用するのが「検索エンジン」。今や、検索結果の上位に表示されることは、銀座の一等地に出店するのと同じくらい、ビジネスにインパクトをもたらすことなのです。
海外では今、「検索体験最適化(SEO:Search Engine Optimization)」という言葉が使われています。これからは、「検索エンジン」に対する最適化ではなく、「ユーザーの検索体験」に対する最適化が求められる時代になると考えられているのです。
SEOを通じて検索上位を実現し、ビジネスの成長に繋げるには専門的なノウハウと戦略的な取り組みが不可欠です。しかし、社内にマーケティングの専門人材がいなかったり、ノウハウ不足でSEOに思うように着手できない企業も少なくないでしょう。
そのようなお悩みを抱えている企業様には、イノーバの「伴走型マーケティング支援サービス」がおすすめです。イノーバではSEOを含むデジタルマーケティング領域の豊富な実績とノウハウを持つプロフェッショナル集団が、御社の事業成長のために伴走します。現状分析から戦略立案、施策実行、効果測定までを一気通貫でサポートし、御社の売上アップ・利益最大化を実現します。
SEOをビジネス成長の武器にしたい方は、ぜひ一度イノーバにご相談ください。私たちが培ってきた知見を惜しみなく提供し、御社の事業を力強く支援させていただきます。
他にもこちらの記事をぜひお読みください
SEO目的でのオウンドメディア活用はこちらの記事を参考にお読みください。
イノーバマーケティングチーム
本ブログでは、豊富な支援実績から得られたデータに基づき、イノーバ独自の知見や現場で使える実践的なノウハウを積極的に発信。「読者の課題解決」を第一に、正確性と信頼性の高い情報提供に努めています。
_%E6%9C%80%E7%B5%82%E7%89%88.jpg?width=90&name=%E6%9B%B8%E7%B1%8D%E8%A1%A8%E7%B4%99(%E5%B9%B3%E9%9D%A2)_%E6%9C%80%E7%B5%82%E7%89%88.jpg) |
 |
 |

