
最近、大規模言語モデル(LLM)の進歩が停滞しているのではないかという見方が広がり、このコラムでも、その問題を取り上げました(イノーバウィークリーAIインサイト No.29 「LLMは壁に突き当たっているのか?」)。しかし、2024年12月20日(米国時間)に発表されたOpenAI o3は、そんな見方を一変させ、AGI(人工汎用知能)に近づく新たなパラダイムを示すものとして注目されています。
この記事では、o3の驚くべき性能とその仕組みについての識者の考察、さらには、残っている課題や今後注目すべきポイントについて解説します。
o3の驚異的な性能向上
o3は、OpenAIが今年9月にリリースした推論能力に優れたAIモデルo1をさらに強化したモデルです。ちなみに、o2という名称をスキップしたのは、英国の携帯通信会社O2と商標権問題が生じる可能性があったためとのことです。
o3には、標準版の「o3」と小型モデル「o3-mini」の2種類があります。いずれもまだ一般公開はされておらず、まずは、安全性とセキュリティを検証するプログラムを通じて研究者向けに早期アクセスが提供される予定です。順調に進めば、2025年1月末にo3-miniの提供を開始し、その後フルモデルがリリースされる予定です。
o3は、数学、科学、プログラミングといった専門的な分野で驚異的な性能向上を実現しています。特に注目すべきは、FrontierMathと呼ばれる数学のベンチマークテストでの成績です。FrontierMathは、最近多くのLLMが従来の数学問題ベンチマークで満点近い成績を上げ差が測定できなくなってきたために、開発された特に難解な数学問題で構成された最新のベンチマークです。
これまで最高性能のAIモデルでも正答率約2%に留まっていたこのテストで、o3は25%という驚異的なスコアを達成。現代最高の数学者の一人とされるテレンス・タオ氏でさえ「これらの問題は極めて難しく、AIが解けるようになるまでには数年かかるだろう」と評価していた問題群に対して、予想をはるかに上回る成果を示したのです。
ARC-AGIベンチマークにおけるo3の驚異的な成績
さらにo3の能力を最も劇的に示したのが、以前このコラムで取り上げたARC-AGI(Abstraction and Reasoning Corpus)でのパフォーマンスです。このベンチマークは、AIシステムの抽象化と推論能力を測定するために設計されており、人間には比較的容易に解けるものの、AIにとっては極めて困難なタスクとして知られていました。
OpenAI oシリーズの性能比較(出典 ARC-AGI主催者サイト)
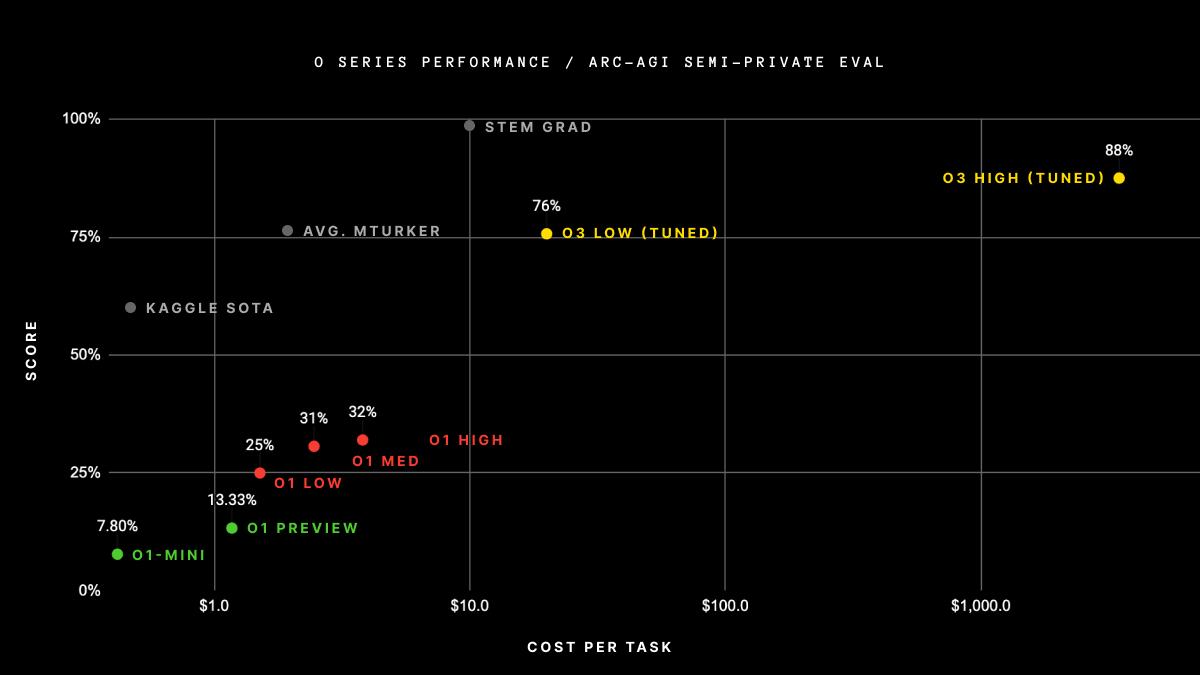
o3は、ARC-AGIの公開テストセットで85%以上の精度を達成した最初のモデルとなりました。これは人間の平均的なパフォーマンス(約85%)に匹敵する成績です。
ARC-AGIの考案者であるフランソワ・ショレは「これは単なる漸進的な改善ではなく、本物のブレークスルーであり、以前のLLMの限界に比べ、AI能力の質的転換を示すものである。o3は、これまで遭遇したことのないタスクに適応できるシステムであり、ARC-AGIの領域においては間違いなく人間レベルのパフォーマンスに近づいている」、さらに「AIの能力に関するすべての直観は、o3によって更新される必要があるだろう」と評価しています。ただし、彼は「ARC-AGIに合格したからといってAGIを達成したことにはならないし、実際のところ、o3はまだAGIではないと思う。o3はまだいくつかの非常に簡単なタスクで失敗しており、人間の知能との根本的な違いを示している」とも述べています。
o3はどのように高い性能を実現しているのか?
「思考の連鎖(Chain-of-Thought)」
OpenAIはo1やo3の仕組みについて詳しい情報を公開していませんが、o1発表時に、推論モデルが「思考の連鎖」と「強化学習」いう手法を使用していると説明していました。
サンタフェ研究所のメラニー・ミッチェル教授の解説によれば、「思考の連鎖」は、タスクを一連のステップに分解し、各ステップで自然言語による「思考」を生成し、それを次のステップの推論に利用する手法です。o1やo3は、人間が問題を解決する際に使った「思考の連鎖」の報告例を集めた大規模なコーパスでトレーニングされていると考えられます。さらにシステムは、強化学習の手法を用いて、「思考の連鎖」の質を評価する「報酬モデル」を学習しているのだろうとミッチェル教授は考えています。
o3では、単一の回答ではなく、同じ問いに対して複数の回答を生成し、最も多く出現する回答を選択することでさらに高い性能を実現しているようです。ARC-AGIのテストでは、低い計算モードでは6個の、高計算モードで最大1,024個のサンプルを生成し、その中から最も頻度の高いものを最終解として選んでいるようです。
テストタイムコンピュート(推論時の計算)
このような「思考の連鎖」の生成は、上述の以前の記事で解説したテストタイムコンピュート(推論時の計算)の一形態です。従来のLLMは、学習時に膨大な計算が必要で長い時間がかかりましたが、一旦モデルが完成し実際に使用する際(推論時)には、それほど大きな計算を必要とせず質問に対する答えを即座に作成していました。
o1とo3のシステムは少し違います。o1やo3も時間をかけて事前学習したLLMを使いますが、実際の利用時に新しい問題が与えられると、「思考の連鎖」を生成するという追加の計算を行います。これをテストタイムコンピュートあるいは推論時計算と呼んでいます。
従来、AIの世界では、事前学習時のデータ量、計算量、モデルサイズを増加させることでモデルの性能が向上するスケーリング則が知られていました。しかし、最近ではデータの枯渇などの問題から、この事前学習時のスケーリング則に限界が見えてきたと懸念されていました。しかし、o1が9月に発表されてから3ヶ月という短期間で発表されたo3が、これだけ高い性能伸長を示したことは、推論時の計算量を増加させれば、性能が向上するという新たなスケーリング則が極めて有効であることを示しています。
それではo3の延長線上にAGI(汎用人工知能)があると考えて良いのでしょうか? いくつかの課題が指摘されています。
o3の課題と今後注目すべきポイント
コストの問題
現状での明らかな問題は、推論時に必要となる大きな計算コストです。ARC-AGIのテストでは、1つの問題を解くのに低計算モードで約17ドル、高計算モードでは数千ドルものコストがかかることが明らかになっています。これは、同じタスクを人間を雇って解く場合のコスト(約5-10ドル)をはるかに上回ります。高計算モードでARC-AGI全400問を解くのに100万ドル以上のコストをかけたことになります。これは、このような人間には簡単なパズルを解くためにかける費用としては現実的とは言えません。
コンピュータチップ(GPU)のコスト性能比の改善や小型モデルの活用によって、推論時の計算コストは今後も速いペースで下落していくと考えられ、やがては人間のコストを下回るかも知れません。しかし、短期的にはこのコスト問題によって、o3を使える分野を限定することになるでしょう。
ARC-AGIでは、新しいタスクを解決する際の計算資源消費を最小化することも望ましいシステムの重要な条件としています。このため、ARC-AGIのコンテストでは、使用できる計算資源に上限を設けていました。o3の高計算モードはこの上限をはるかに超過しています。課題を解くのに必要な計算資源の効率性も今後の開発の一つのポイントになります。
得意分野の偏り
数学やコーディングのように明確な正解が存在する分野では推論時の計算のスケーリングが有効だと考えられます。これとは対照的に、文章作成や言語翻訳のようなタスクでは、推論スケーリングが大きな違いをもたらすとは考えられません。例えば、学習データが不足している言語への翻訳において、その言語の慣用句が分からないためにうまく訳せない場合、モデルの推論能力によってこれを解決することはできないでしょう。
実際、o1は数学、コーディングなどでは、従来モデルに比べて著しい性能向上を示しましたが、文章作成や翻訳などの分野では、改善は見られず、むしろ劣る面も見られました。o3はまだ一般公開されておらず、コーディング、ARC-AGI以外のテストでのパフォーマンスは明らかになっていませんが、他分野でどのようなパフォーマンスを発揮できるのかが注目されます。
もう一つ、今後確認すべきポイントは、OpenAIがo1は従来モデルに比べて日常的な問題でも回答の信頼性が高くなっていると主張していることです。これが事実であればAIエージェントなど実世界でのAIアプリケーションの有用性が向上することが期待されます。
o3はどこまで本当に抽象化や一般化ができているといえるのか?
人間の知性の働きにおいては、抽象化と一般化の能力が重要な役割を果たしています。抽象化とは、個別の事象から本質的な特徴を取り出し、不要な細部を切り捨てる認知プロセスです。一般化は、この抽象化された特徴をもとに、新しい事例にも適用できるパターンを見出すプロセスです。ARC-AGIは、このような抽象化と一般化の能力を測るテストとして考案されました。
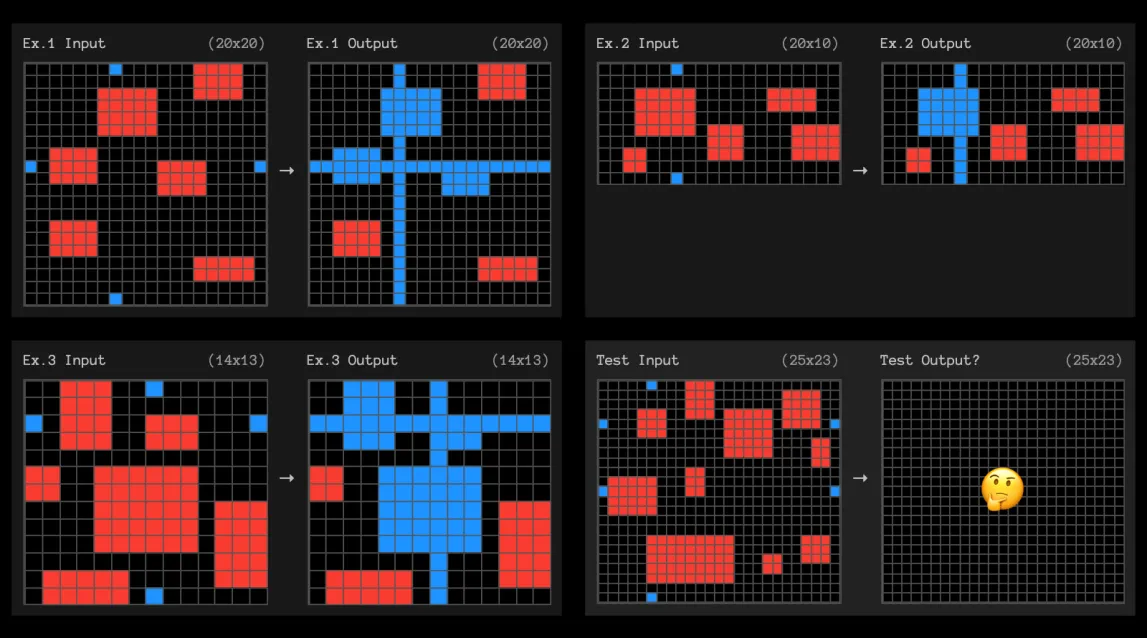
今回o3はARC-AGIで人間を上回るレベルのスコアを達成していますが、不正解だった問題を見ると、非常に簡単な問題で失敗しているケースがありました(例えば下記の問題)。このことは、o3がどれだけ深い抽象化・一般化能力を持っているのかについて疑念を抱かせるものです。
o3が解けなかった問題例
おわりに
OpenAIのo3は、AIの可能性を大きく広げる画期的な技術です。その高度な推論能力は、様々な分野でイノベーションを促進し、私たちの生活に大きな変化をもたらす可能性を秘めています。
ただし、o3の能力はまだ完全には解明されておらず、その可能性と限界については、今後の研究によってさらなる理解が必要です。フランソワ・ショレは、ARC-AGIの次のバージョンARC-AGI-2を開発していることを明らかにしています。初期のデータからは、この新たなベンチマークはo3の高計算モードでも30%以下のスコアしか出せていないそうです(一方、賢い人間なら訓練なしで95%以上のスコアを出せるだろうと言っています)。
Googleや他社もテストタイムコンピュートによって推論能力を強化したモデルに取り組んでおり、今後の研究開発の進展が、より一層注目されます。
参考記事:
https://arcprize.org/blog/oai-o3-pub-breakthrough
https://aiguide.substack.com/p/did-openai-just-solve-abstract-reasoning
https://garrisonlovely.substack.com/p/we-are-in-a-new-paradigm-of-ai-progress
