
OpenAIは米国時間2024年9月12日、新たな生成AIモデル「o1 (オーワン)」を発表しました。
本記事ではo1の概要、何が新しいのか、そして今後注目すべきポイントについて、既に出ている分析・レビュー記事を参考に探ってみたいと思います。
OpenAI o1概要
OpenAI o1は応答する前に考える時間をかけ、従来モデルでは対応できなかった難度の高い科学、コーディング、数学の問題を解決することができます。
テスト中の次回アップデート版は、物理や化学、生物学の難しいベンチマークテストタスクにおいて、博士課程の学生と同等の性能を発揮しているとのことです。また、国際数学オリンピック(IMO)の予選試験を解かせたところ、既存モデルのGPT-4oの正答率はわずか13%だったのに対し、今回の推論モデルでは83%に達しました。コーディング能力にも優れ、Codeforcesの競技では89パーセンタイルに達したとのことです。
ChatGPT Plusに加入しているユーザーは、「o1-preview」と軽量版「o1-mini」の2つが選べるようになっています。「o1-preview」は、幅広い一般知識を学習しています。「o1-mini」はよりSTEM分野(科学、技術、工学、数学)に特化していますが、「o1-preview」に比べて、応答が速く、低コストです。o1は現在のところ、Webの情報閲覧や、ファイル/画像のアップロードといったChatGPTにある機能は備わっていませんが、今後追加していく計画とのことです。
OpenAI o1は従来のChatGPTのモデルを置き換えるものではなく、新たなシリーズとして位置づけられています。すべてのタスクにおいて、GPT-4oなどChatGPTの既存モデルより優れているわけではなく、例えば文章作成についてはGPT-4oが向いているとのことです。コスト的にはGPT-4oの100万トークン当り$0.15に対してo1-previewは$15と100倍高く設定されています。
新たなスケーリング則
o1は、回答する前に、複数の内部推論ステップを実行することによって、より複雑な問題を解決するという新たなコンセプトに基づいています。従来の大規模言語モデル(LLM)は、問題の複雑さに関わらず、常に瞬時に回答を生成していました。o1では、人間が複雑な問題に対応する時に時間をかけて考える、いわゆる「システム2思考」ができるようになったといえます(システム1思考とシステム2思考については、「AIが苦手なパズル:ARC-AGIベンチマークが示唆するAGIに向けての課題」を参照ください)。
LLMの世界では、モデルのサイズと学習時のデータ量と計算量を増加させればさせるほど、モデルの正確性が向上するスケーリング則が知られていました。このため、OpenAI、Anthropic、Googleなど生成AIのリーダー達は、NVIDIAのGPUを搭載したサーバー群に多大の投資を行い、より高性能のLLM開発を競ってきました。
今回OpenAIが発見したのは、学習時だけでなく、回答を生成する推論時にも「考える」ことに費やす計算量(=計算時間)を増やせば、それだけ性能が向上する独自のスケーリング則があるということです。
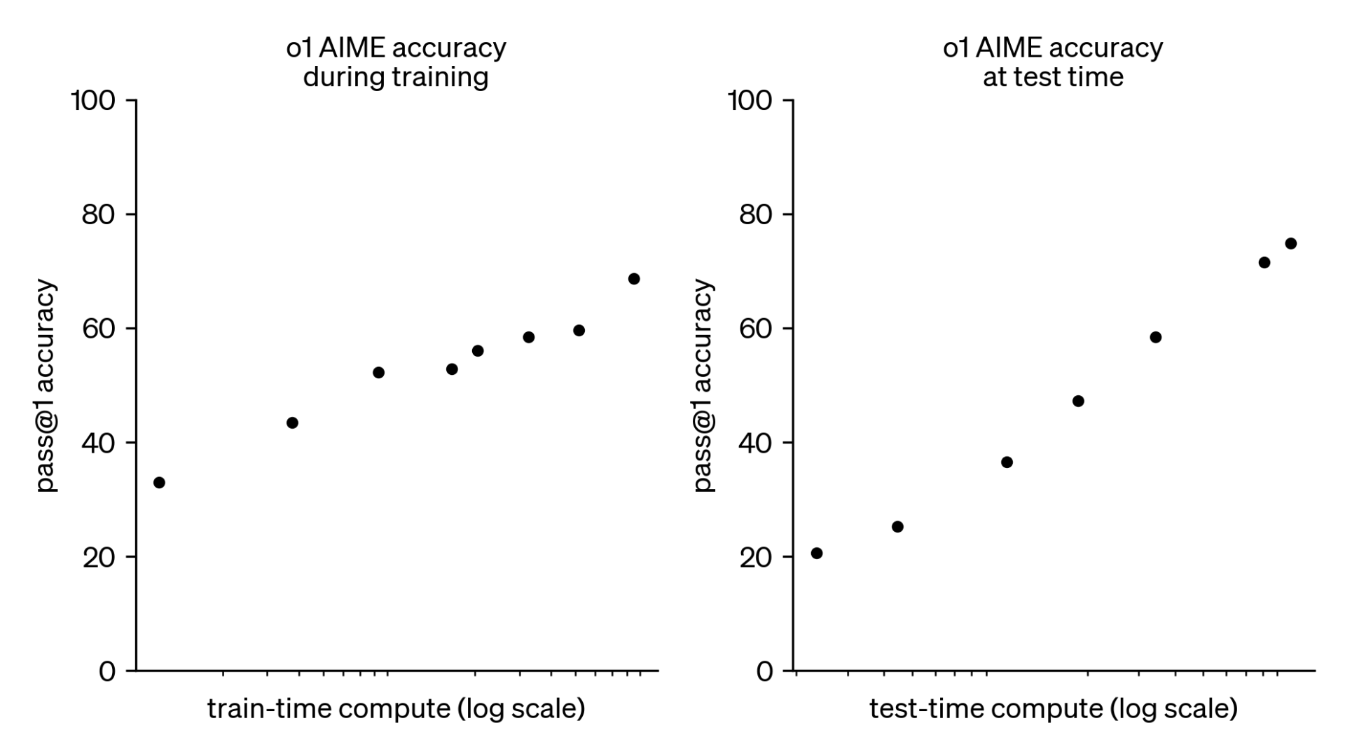
o1の性能は事前学習時(左)も推論時(右)も計算量の増加と共にスムーズに向上している
Learning to Reason with LLMs | OpenAI
ペンシルべニア大学ウォートン・スクールのイーサン・モリック准教授はo1発表後のブログ記事で、新たに推論時のスケーリング則が見出されたことは、「AIの能力が今後数年で飛躍的に向上することを示しており、より強力なAIの開発競争は衰えることなく継続し、社会、経済、環境に広範囲な影響を及ぼすことは間違いないだろう」と言っています。
Scaling: The State of Play in AI - by Ethan Mollick
思考の連鎖(Chain of Thought)
OpenAIはo1の推論プロセスについて次のように説明しています。
人間が難しい質問に答える前に長い時間考えるのと同じように、o1は問題を解決しようとするときに思考の連鎖(chain of thought)を使う。強化学習を通じて、o1は思考の連鎖を磨き、使用する戦略を洗練させることを学ぶ。間違いを認識し、修正することを学ぶ。難しいステップをより単純なステップに分解することを学習する。現在のアプローチがうまくいかないときは、別のアプローチを試すことも学習する。このプロセスは、モデルの推論能力を劇的に向上させる。
Learning to Reason with LLMs | OpenAI
LLMの回答の向上させるプロンプト手法として、「ステップバイステップで考えろ」という思考の連鎖が効果的であることが以前から良く知られていました。今回、OpenAIが行ったのは、o1モデルにまさにこのような「思考」プロセスを組み込むことでした。
Googleの研究者でAIの汎用的な推論能力を測るARC-AGIを考案したことで知られたフランソワ・ショレ氏は、OpenAIは、人間の推論をまねた思考の連鎖を人工的に大量に生成し、強化学習を通じてさらに深く学習させているのだろうと考えています。
OpenAI o1 Results on ARC-AGI-Pub
OpenAIは、推論時にも、強化学習を用いて思考の連鎖を磨いて、戦略を洗練させているといっています。適用した解法が間違っていれば、別の解法を探索して適用するといったプロセスを自動反復することによって、最終的な回答に辿り着くと考えられます。
推論時の思考の連鎖の反復プロセス:Reasoning - OpenAI API
o1の使用例
OpenAIは暗号の解読、難しい論理パズル、ビデオゲームのコーディング、量子物理学の問題など従来のGPT4oではできなかったタスクを解決している使用例をいくつか公開しています。
複雑な論理パズル、ビデオゲームのコーディング、トリッキーな言葉に関する質問など
量子物理学の問題
o1が科学や論理的な問題に優れていることはわかりましたが、ビジネスへの適用についてはどうでしょうか?
下記のスレッドでは、(1)病院の医師・スタッフのスケジュール最適化、(2)電力網の需給バランス、(3)eコマース会社倉庫の最適レイアウト、(4)企業の新規プロジェクトの投資対効果分析といった複雑なビジネスの分析問題をo1に解かせています。
この中から、(3)eコマース会社倉庫の最適レイアウトについて少し詳しくみてみましょう。プロンプトは次のようなものです。
「あなたは大きなeコマース会社の倉庫でのオーダーピッキング作業時間を最短化するために在庫レイアウト最適化の仕事を任されたロジスティクスエンジニアです。倉庫は毎日平均5万件の注文を処理しています。その他、考慮すべきパラメータは以下です:
(倉庫の寸法、保管システム、商品点数、ピックキング作業方法、無人搬送車の数、速度、積載量などのスペック、平均商品数、商品の人気度の分布などの注文の特徴、商品のサイズ、重要のカテゴリーと分布など詳細データが与えられているが省略)
タスク:
- 倉庫レイアウトを最適化する数理モデルを商品の人気度、サイズ、重量を考慮して作成してください。
- 目的関数と制約条件を定義してください。
- あなたが策定した最適レイアウト下とランダムなレイアウト下での平均的なオーダー当りのピッキング時間をそれぞれ算定してください。
- あなたの最適レイアウト下での倉庫の最大スループット(一時間当りの処理オーダー数)のシミュレーションを行ってください。無人搬送車の数を20%増やすと、スループットはどう変化しますか?
- 商品の人気度の分布パラメータ(パレートαパラメータ)の変化が、最適レイアウトとピッキング時間にどのように影響するかセンシティビティ分析を行ってください。
- 頻繁に同時注文される商品をグルーピングするクラスタリングアルゴリズムを作成してください。これによって平均ピッキング時間はどのように影響されますか? (さらに設問が続くが以下省略)」
これらの設問に対して、o1は216秒間考えて、要求通り、最適化する目的関数、最適なレイアウトの戦略、オーダー当りの処理時間、倉庫のスループット、無人搬送車の数を増やした場合の影響など、それぞれ数式を定義し、具体的な数値に基いた計算結果を出しています。

Eコマース会社倉庫のレイアウト最適課題の回答の一部
この分析結果が本当に正しいのか私には判断できませんが、o1は設問の意図を理解し、高度な分析を行っているように見えます。ただし、このような分析を引き出すためには、専門知識を持ったエキスパートが、正しく問題を設定し、必要な前提条件をプロンプトで与える必要があるでしょう。
今後の注目点
OpenAI o1は、従来のLLMの弱点だった論理的推論能力を備える画期的な新たな技術の方向性を示すものといえます。しかし、まだ完成された製品とはいえず、文字数のカウントなど単純な問題で間違えを犯す例もいくつか報告されています。また、ハルシネーションや事実誤認の問題も解決されていません。
今後、いくつかのポイントに注目して見ていく必要があるでしょう。
o1活用のベストプラクティス
o1と他のモデルを、どのように使い分けるか?どのようなユースケースに適しているか、プロンプトの方法についても、従来モデルとは異なるガイドラインが出されており、ベストプラクティスが明確になるまでには、しばらく時間はかかりそうです。
今後の製品アップデート
今回のo1はpreviewという名称が示す通り、初期の試験的なリリースであり、今後のアップデートでどのように機能が改善、追加されるかによって、活用できる分野も拡大していくでしょう。尚、OpenAIは、o1とは別にGPTの次期モデル (GPT-5或いはコードネーム「Orion」)を開発していることが知られています。GPT-5をベースとしたo1の後継モデルもいずれ出てくるものと期待されます。
他社の動き
他の先端モデル開発者も、思考連鎖の推論を適用したのモデルを開発し、同様の成果を目指してくることは十分に考えられます。
AIエージェントへの活用
o1の複雑なタスクを分割したり、推論を反復したりして正確性を上げる技術はAIエージェントに必要とされる能力です。真に自律的なエージェントにo1がどのように活用されるかが注目されます。
おわりに
OpenAI o1の登場は、AIの進化における重要な一歩を示しています。複雑な推論能力を持つこのモデルは、科学、技術、ビジネスの分野に大きな影響を与える可能性を秘めています。しかし、その真価を発揮するには、適切な使用方法の理解と、専門知識を持つユーザーの関与が不可欠です。
日本のマーケターや企業にとって、o1のような高度な推論能力を持つAIの登場は、新たな機会と課題をもたらします。製品開発、市場分析、戦略立案など、複雑な意思決定を必要とする領域での活用が期待されます。一方で、AIの進化に伴う倫理的問題や、人間の専門性との共存のあり方についても、真剣に考える必要があるでしょう。
