
OpenAI、Google、Anthropicといった主要AI企業が次世代大規模言語モデル(LLM)の開発において、期待されていた大きな性能改善が達成できず、技術的な壁に直面しているというニュースが最近いくつかのメディアで報道され大きな話題になっています。
これまでAI企業は「より大きなモデル、より多くのデータ、より強力なコンピューティングパワー」によって性能が向上するという「スケーリング則」に従って、投資を拡大して新世代のLLMの開発を進めてきましたが、今、転換点が訪れているのでしょうか?
今週のAIインサイトでは、この技術的転換点の詳細と、その影響について考察していきます。
性能向上ペースの鈍化
テクノロジーに特化したニュースサイトThe Informationの記事は、OpenAIの研究者からの情報として、開発中の次期モデル(コードネーム「Orion」)は、GPT-3からGPT-4にバージョンアップした際に見られたような大幅な性能向上が達成できていないようだと伝えています。さらに、コーディングなど一部の分野では、以前のモデルより優れているとは言えないかもしれないとのことです。これは、新モデルは以前のモデルに比べ、サイズも大きいため回答を生成する運用コストも高くなっていることを考えると大きな問題といえます。
この問題はOpenAIに限った話ではありません。ブルームバーグ記事によれば、Googleの次期Geminiモデルも社内の期待値を下回っているとされ、AnthropicのClaude上位モデル Opusの開発スケジュールにも遅れが生じています。
ロイター記事は、OpenAI共同創業者のイリヤ・サツキバー氏がインタビューで、膨大なデータを使ってLLMを訓練する段階の「事前学習」のスケールアップの結果が頭打ちになっていると述べたと報じています。サツキバー氏は今年初めにOpenAIを離れ、Safe Superintelligence (SSI)を設立していますが、スケーリング則の初期の提唱者として広く知られています。サツキバー氏は「2010年代はスケーリングの時代だったが、今や驚きと発見の時代に再び戻った。誰もが次のものを探している」と言っています。
データの壁の問題
これらの記事で引用されている専門家や内部関係者たちは、事前学習の問題の中心は、新しいLLMが学習するための新しく質の高いデータが不足していることだと言っています。イノーバウィークリーAIインサイト第26回で説明した「データの壁」の問題です。 これまでAIモデルは、ウェブサイト、書籍、その他のパブリックドメインのテキストデータを活用してきましたが、こうした既存のデータソースはほぼ使い尽くされた状態にあるというのです。
この問題に対する一つの解決策として、合成データ が注目されています。これは、LLMによって生成されたデータを、次世代のLLMの開発に利用するというアイデアです。しかし、合成データは、量の問題を解決できても質と多様性の問題を解決できません。また、合成データの使用はモデルの性能低下をもたらす「モデル崩壊」などのリスクが懸念されています。
先端AIモデル企業やScale AIなどのデータ専門の企業は多数の博士号取得者や、弁護士、会計士など各分野の専門家を使って合成データを検証し修正や補完を行って質の高いデータを確保しようとしていますが、これは大きなコストと時間のかかるアプローチです。
テストタイムコンピュート:新たなスケーリング則
手法の概要
学習時の問題を克服する有力な方法として、研究者らはモデルを使う段階(推論時あるいはテスト時という)にAIモデルを強化する技術の「テストタイムコンピュート」を模索しています。これは、今年9月にリリースされたOpenAI o1モデルで使われている手法です。
イノーバウィークリーAIインサイト第21回で説明したように、o1は回答する前に、「考える」時間を費やすことによって、より複雑な問題を解決します。即座に単一の答えを選ぶのではなく、モデルがリアルタイムで複数の可能性を生成、評価することで最終的に最善の方法を選択する方法です。
o1発表時にOpenAIが公開した下記のグラフは、学習時だけでなく、回答を生成するテスト時にも「考える」ことに費やす計算時間(=計算量)を増やせば、それだけ性能が向上する新たなスケーリング則があることを示しています。
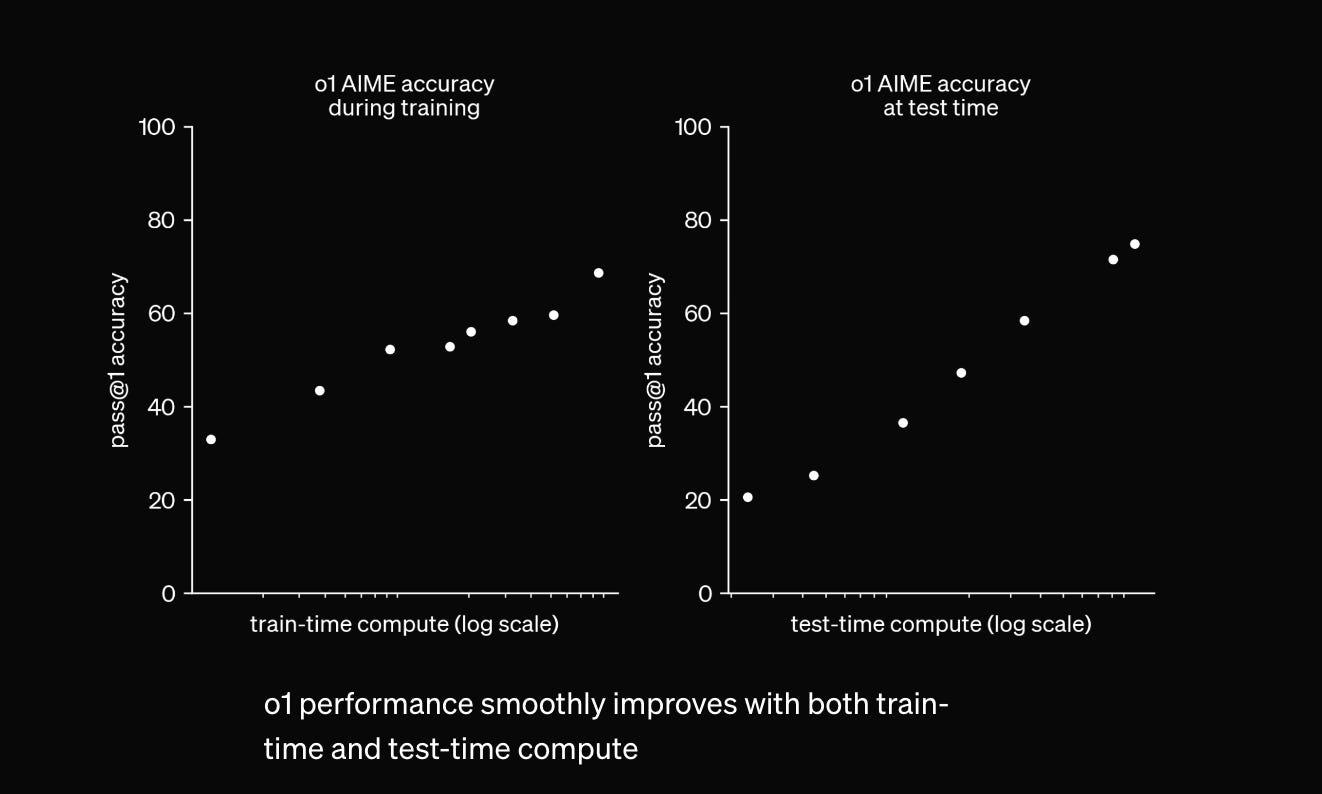
o1の性能は事前学習時(左)もテスト時(右)も計算量の増加と共にスムーズに向上している
Learning to Reason with LLMs | OpenAI
この方法により、o1モデルは、数学やコーディングの問題、あるいは人間のような推論や意思決定を必要とする複雑な操作のような困難なタスクにより多くの処理能力を割くことでベースモデルが対応できなかった問題やタスクを解決することができます。
OpenAIの研究者でo1開発に携わったノーム・ブラウンは、10月にサンフランシスコで開催されたTED AIカンファレンスで、ポーカーのような課題では、「モデルに20秒間考えさせるだけで、10万倍大きなモデルで10万倍長く学習させた場合と同等の性能向上が得られた」と語りました。
課題
これは、新しいスケーリング則が活用できるようになれば、古いスケーリング則が働かなくなっても問題ないということを意味するのでしょうか?「そう簡単ではない」とテクノロジーに詳しいジャーナリストのギャリソン・ラブリー氏は言います。
上のグラフでy軸は対数スケールではないのに、x軸は対数スケールであることは、直線的な性能向上を実現するために、指数関数的に計算量を増やさなければならないことを意味しています。テスト時に計算時間をつぎ込めば、AIが人間にも難しいような科学技術の難題を解けるようになるとしても、それが経済的に見合うコストで実現できるかは明らかではありません。
また、もしベースモデルの性能改善が本当に頭打ちになっているのであれば、将来計算コストが何桁も下がったとしても、科学技術フロンティアを拡げるようなAGIが達成できるかどうかは明らかでないとラブリー氏は言っています。
新たな技術的アプローチの模索
マーケティングAIインスティテュートのポール・レッツァーは、テストタイムコンピュート以外にも重要なブレークスルーが期待できる領域をいくつか挙げています。
マルチモーダルトレーニング
- テキスト、動画、音声、画像を同時に学習
- より豊かな文脈理解の実現を目指す
大規模モデルと小規模モデルの連携
- 最先端LLMを「指揮者」として活用
- 専門化された小規模モデルを組み合わせる新しいアプローチ
自己対戦と再帰的な自己改善
- GoogleがAlphaGoなどのゲームプレイAIで培った技術を活用
- モデルの自律的な性能向上を目指す
また、AI各社が今後の鍵として力を入れている領域として、AIエージェントがあります。AIの推論・計画能力と外部ツールの連携によって、ユーザーに代わってフライト予約やメール送信を行うシステムを実現しようという考え方です。Anthropicは、Claudeで既に「コンピュータ使用」機能を提供しています。これに対し、OpenAIやGoogleもツール使用機能の強化を計画しており、近くリリースされると言われています。
これは企業にとって何を意味するか
このような技術的転換点は、企業のAI戦略にどのような影響を与えるのでしょうか。
ポール・レッツァーは、「来年、AIが大きく進歩するかどうかは、ビジネスリーダーにとってさほど重要ではありません。現在のモデルの活用度が極めて低い状況で、今あるAIで創出できる価値は依然として膨大かつ未開拓です」と言います。
ペンシルべニア大学ウォートン・スクールのイーサン・モリック准教授も同様に、仮に今日、AIの開発が止まったとしても、現在のAIは、今後、何年もの間、私たちの仕事や社会に大きな変化をもたらすだけの能力をすでに持つに至っていると考えています 。
私たちにとって、現在の最優先課題は、まず、現状のAIツールの活用度を上げることだといえるでしょう。多くの企業では、AIの導入は試験的な段階にとどまっており、組織全体での効果的な活用には至っていません。特定の業務プロセスでの実証実験から始め、成功事例を積み上げていくアプローチが有効です。同時に、組織的な活用体制の整備と人材育成も急務となります。
おわりに
今明らかになりつつあるAI開発における転換点は、OpenAIやAnthropicのリーダーたちが示してきた、数年以内にも気候変動や難病治療の問題を解決してくれるAGI(汎用人工知能)が実現するという見方に、重要な疑問を投げかけています。
学習時の単純なスケーリングによる性能向上が限界に近づく中、AGI(あるいはより高度なAI)への道筋は以下の観点から注目していく必要があるでしょう:
新しい学習アプローチの有効性
- テストタイムコンピュートなど、新たなスケーリング則の実用性
- マルチモーダル学習や大規模モデルと小規模モデルとの連携など、革新的アプローチの進展
データの質と多様性
- 高品質な学習データの確保手法
- 合成データの活用とその限界
モデルの信頼性
- 回答の正確性(ハルシネーション問題)
- 推論過程の透明性と説明可能性
特にハルシネーション(AIが自信を持って誤った情報を提供する問題)は、AGIへの道のりで克服すべき重要な課題の一つです。現在のAIモデルは、しばしば誤った情報を高い確信度で提供することがあり、これはAIの実用化において重大な懸念事項となっています。
AIの進化は確実に続きますが、その道筋は私たちが当初想像していたよりも複雑かもしれません。しかし、それは必ずしもネガティブな状況ではありません。むしろ、より実用的で持続可能なAI活用の方向性を示唆しているとも言えます。
企業は、このような技術的な転換点を理解した上で、現実的かつ効果的なAI活用戦略を構築していくことが求められています。それは、劇的な技術革新を待つのではなく、既存の技術を着実に活用しながら、新しい可能性を探索していく姿勢と言えるでしょう。
