
中国発のAIスタートアップDeepSeekが2025年1月20日 (日本時間)に公開した推論能力に優れた大規模言語モデル「DeepSeek-R1」が、AI業界の構図を大きく揺るがしています。DeepSeek-R1はOpenAIの推論モデル「o1」に匹敵する性能を持ちながら、オープンソースとして公開され、無料でダウンロードでき商用利用も可能です。
米国ではDeepSeekがアップルのApp Store無料アプリランキングで1位になるなど注目を集めています。DeepSeekの今回の発表は、単なる技術的進歩以上の意味を持っています。AIの市場構造や米中のAI覇権をめぐる争いにまで影響を及ぼす可能性があるからです。
米国の有力ベンチャーキャピタル「アンドリーセン・ホロウィッツ」のマーク・アンドリーセン氏は、「DeepSeekはAIのスプートニク的瞬間だ」と「X」に投稿し、1957年にアメリカがソ連に人工衛星の打ち上げで先行を許した「スプートニク・ショック」になぞらえています。
本稿では、DeepSeekの最近の発表の意味と影響を探ります。
DeepSeekとはどんな会社か
DeepSeekは、中国の投資ファンドHigh-Flyer Quant(幻方量化)から2023年にスピンオフして生まれたスタートアップです。創業者の梁文峰(Liang Wenfeng)氏は、AIを駆使した運用戦略で、High-Flyer Quantを中国最大級のヘッジファンドへと成長させた人物です。そして、クオンツ投資から得たAI活用経験と潤沢な資金を武器に、AI開発に乗り出したのです。
DeepSeekの各モデルの特徴と性能
DeepSeek-R1
DeepSeek-R1は、推論モデルと呼ばれる新しいタイプのAIモデルです。従来の大規模言語モデル(LLM)が即座に回答を生成するのに対し、このタイプのモデルは人間のように段階的に思考を進めていきます。例えば、複雑な数学の問題を解く際、途中の計算過程を示しながら、時には自己修正も行います。
思考の連鎖を活用したこうしたアプローチにより、特に数学、コーディング、科学的推論といった分野で高い精度が実現できます。R1はこの分野で先行していた、OpenAI o1に匹敵する性能を、数学、コーディング、推論タスクにおいて達成しています。さらに、APIアクセス料金をo1の約27分の1に抑えることで、極めて高い費用対効果を提供しています。
DeepSeek-R1は、2024年12月26日に公開されたDeepSeek-V3をベースに、強化学習と教師ありファインチューニングを組み合わせた多段階アプローチを採用することで、高い推論能力を獲得しています。
具体的には、DeepSeek-V3をベースにまず強化学習のみを用いてDeepSeek-R1-Zeroとよばれるモデルを開発しました。この段階で既に高い推論能力を獲得しましたが、応答の繰り返しや可読性に問題が残っていました。ここから、さらに教師ありファインチューニングや複数段階の強化学習を行うことで、推論能力と構造化された出力を両立したDeepSeek-R1を完成させました。
DeepSeek-V3
DeepSeek-V3は、6710億という業界最大級のパラメータを持ち、14兆8000億トークンでトレーニングされたLLMです。DeepSeek-V3は、OpenAIのGPT-4oに匹敵する、あるいは場合によっては上回る性能を発揮します。
DeepSeek-V3のトレーニングには、NVIDIAのGPU「H800」を約278万8000時間分の計算が使われました。これは約557万ドル(約8億6000万円)の費用に相当します。これは、他の最先端モデルのトレーニングコストが数億ドル(数百億円)に及ぶのと比較して、非常に低い金額です。
DeepSeek-V3がトレーニングコストを安く抑えられた理由は、DeepSeekが公開している技術レポートで明らかにされているさまざまな工夫によるものです。例えば、「Mixture-of-Experts(MoE)」と呼ばれる、まるで専門家チームのように、必要な部分だけを使う賢いモデル設計を採用しているほか、FP8と呼ばれる、少し精度が低い計算方法を、モデル全体に適用することで、計算速度を向上させ、メモリ使用量を削減しています。 通常、精度が低いと結果が悪くなってしまいますが、DeepSeek-V3は、重要な部分では高い精度を保ちつつ、それ以外の部分ではFP8を使うという工夫によって、精度を落とさずにコストを削減することに成功しました。
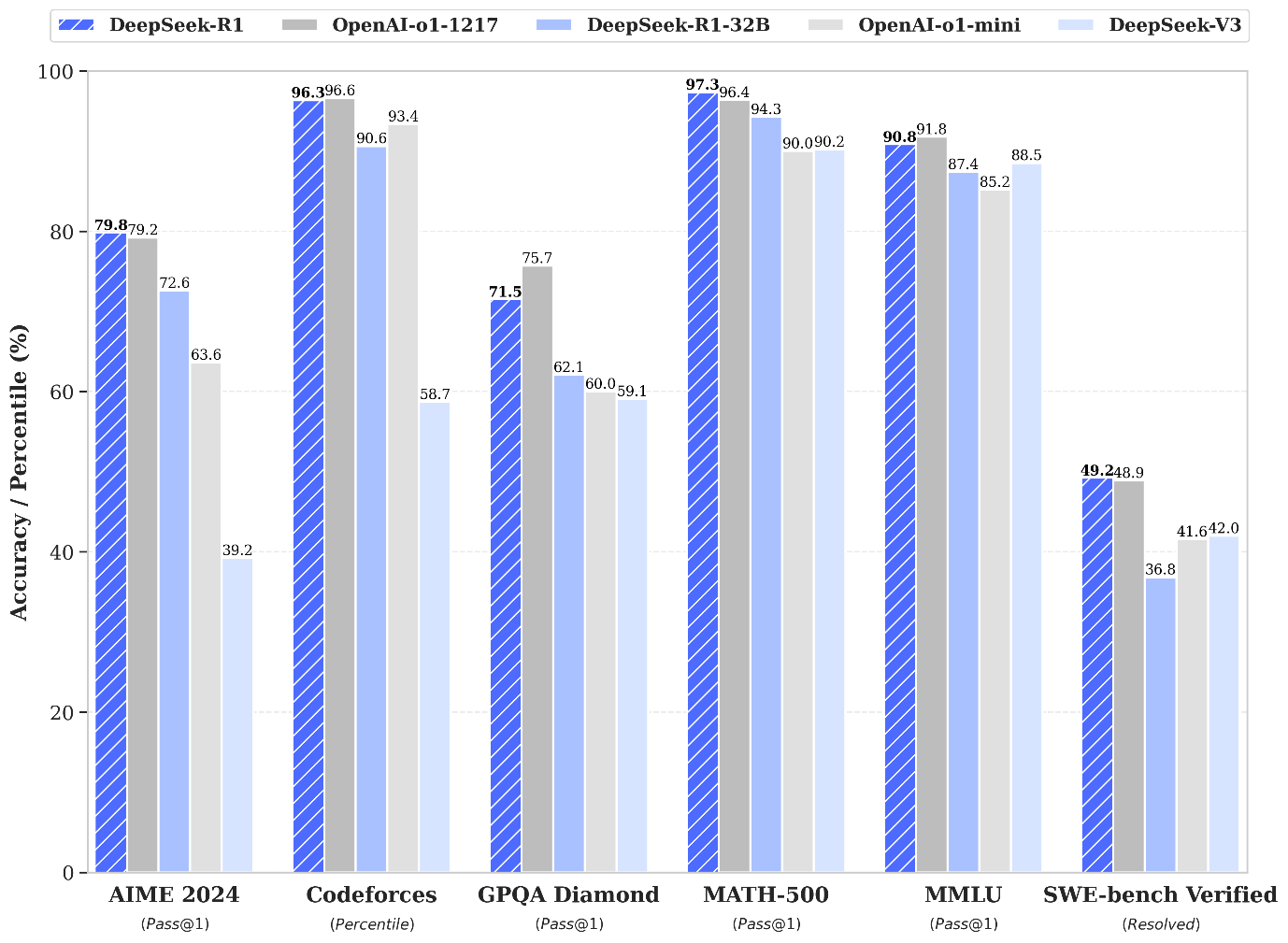
(DeepSeek-R1/V3とOpenAI o1のベンチマーク性能比較 出典 DeepSeek)
DeepSeek-R1-Distillモデル(蒸留モデル)
DeepSeekは、6710億パラメータの大規模モデル「R1」に加え、その能力を継承した小型モデル群も展開しています。これらは「蒸留モデル」と呼ばれ、R1の高度な推論能力を、より小さなモデルに効率的に移植したものです。
既存オープンソースLLMの「Qwen」「Llama」をベースに開発されたこれらの蒸留モデルは、1.5Bから70Bまでの6つのサイズで提供され、小さいものはノートPCでも動作可能です。
DeepSeekによれば、これらのモデルはオープンソースの既存モデルを性能面で凌駕し、OpenAIのo1-miniと同等の能力を持っています。
DeepSeekショック
DeepSeekの最近の発表は、AI業界は新たな局面を迎えています。特に価格設定、開発競争、米中間のAI覇権争い、株式市場や投資の観点から、大きな変化をもたらす可能性があります。
1.価格破壊がもたらす影響
DeepSeek-R1は、チャットサービスは無償、APIアクセス利用料金も入力トークン100万あたり0.55ドル、出力トークン100万あたり2.19ドルとOpenAI o1の約27分の1と極めて安い価格で提供されています。DeepSeekの低価格モデルは、AIサービスの価格競争を激化させ、AIの普及を加速させる可能性があります。低コストで高性能なAIモデルが利用可能になることで、様々な産業でのAI導入が促進され、新たなビジネスモデルが生まれる可能性があります。
また、DeepSeekによる価格破壊によって、OpenAIなどの既存のAI企業は価格競争を強いられることになり、事業計画の見直しを迫られる可能性があります。
2.今後のAI開発競争にもたらす影響
DeepSeekは、R1モデルをMITライセンスで公開し、開発手法についても技術レポートや論文で詳細に公開しています。これにより、企業や研究者はDeepSeekの技術を基に独自のモデルを開発・改良することが容易になりました。
特に、今回のR1モデルの開発プロセスでは、コストや手間のかかる教師ありファインチューニングのプロセスをかなり限定しても大規模な強化学習を行うことで、推論の性能を上げられることが確認されました。この技術は他の研究者にとって非常に参考になります。
また、DeepSeek-R1の蒸留モデルは、比較的容易に高性能の小型モデルを開発できることを示しました。これにより、巨大な投資なしでも先端AIモデルの開発が可能になる道が開かれました。
オープンソースのモデルがプロプライエタリモデルを凌駕する可能性を示しており、AI技術の進歩が一部の企業に独占されるのではなく、より広く共有される未来を示唆しています。DeepSeekの技術公開は、AI開発の民主化を促進し、より多くのプレイヤーがイノベーションに参加することを可能にします。これは、AI技術の進化を加速させ、多様な応用を生み出す原動力となるでしょう。
3.米中のAI覇権争いへの影響
DeepSeekの成功は、米国がAI分野で決定的な優位性を持っているという認識に疑問を投げかけています。DeepSeekが、米国からの輸出規制を受けながらも、高性能なモデルを開発した事実は、米国の制裁が中国のAI技術の進歩を妨げることができないことを示唆しています。
DeepSeekの成果は、AI開発においてハードウェアの量だけでなく、ソフトウェアの革新や効率性が重要であることを示しており、米国のAI戦略に対する再考を促す可能性があります。
一方で、DeepSeekのモデルには、中国のインターネット規制に準拠して、政治的にセンシティブな質問には回答しないという制限があります。中国の企業であるため、データセキュリティやプライバシーの問題が懸念される可能性があります。これは、中国発のAI技術のグローバルな普及における課題を示しています。
4.株式市場やAI投資環境への影響
DeepSeekの低コストでのAIモデル開発能力は、アメリカのテクノロジー企業がAI開発に多額の投資を必要とするという従来の認識を覆し、投資家の間で警戒感が高まっています。また、低価格のAIモデルの登場は、AI関連ビジネスの成長を加速させる可能性がある一方で、既存のAI企業や関連企業にとっては競争圧力となる可能性があります。
米国時間1月27日の取引で、Nvidiaの株価が約17%下落し、市場価値が約5,888億ドル減少しました。これは、一日の株式市場における一社の株式の損失額としては過去最大です。また、MetaやAlphabet(Googleの親会社)などのテクノロジー企業の株価も大幅に下落しました。
アメリカのテクノロジー株が大幅に下落した一方で、ヘルスケアや消費財関連の企業の株価は上昇しました。これは、AI技術の進歩がテクノロジー業界に大きな影響を与える一方で、他の業界には比較的影響が少ない可能性があることを示しています。AIデータセンターの電力需要増加により、エネルギー関連企業の株価が上昇していましたが、DeepSeekの発表後、これらの企業の株価も急落しました。
一部の投資家は、DeepSeekの発表を受けて、過剰な売りが出ている可能性があると指摘しており、今後の市場の動向を注視する必要があると述べています。しかし、DeepSeekのような企業が急速に成長していることは、AI技術の過熱やバブルのリスクを示唆する可能性があり、投資家は慎重な判断が求められます。
おわりに
DeepSeekの登場は、AI業界に大きな転換点をもたらそうとしています。高性能なAIモデルを低コストで開発し、オープンソースとして公開するという同社のアプローチは、AI技術の普及を加速させる可能性を秘めています。特に、推論に特化したDeepSeek-R1の公開は、AIの利用コストを大幅に引き下げ、より多くの企業や個人がAI技術を活用できる環境を整えつつあります。
一方で、DeepSeekの成功は米中のAI覇権争いにも新たな展開をもたらしています。米国の輸出規制下でも、革新的なソフトウェア技術により競争力のあるAIモデルを開発できることを示したことは、AI開発における従来の常識を覆すものでした。この影響は株式市場にも波及しており、主要テクノロジー企業の今後の資金調達にも大きな影響を与える可能性があります。
DeepSeekの成功は、AI開発において、潤沢な資金力や最先端のハードウェアだけが成功の鍵ではないことを示しています。効率的な開発手法とオープンな技術共有の重要性が増す中、AI技術の進化はさらに加速していくことでしょう。
▼参考記事
https://www.interconnects.ai/p/deepseek-r1-recipe-for-o1
https://www.ignorance.ai/p/r1-is-reasoning-for-the-masses
https://www.interconnects.ai/p/deepseek-v3-and-the-actual-cost-of
https://importai.substack.com/p/import-ai-397-deepseek-means-ai-proliferation
https://edition.cnn.com/2025/01/27/tech/deepseek-stocks-ai-china/index.html
